기존에 API 요청 코드들을 작성할 때에는 각 요청마다 method와 credentials와 같은 config 코드들을 작성해야 했고, 반환할 에러 타입들도 각각 작성해주어야 했습니다. 추가로 Next.js의 서버 컴포넌트와 같이 쿠키가 자동으로 실려가지 않는 상황에 대비하기 위한 코드들도 작성해야 했습니다.
따라서 API 관련 코드를 작성하는 개발자들은 각 API가 어디서 쓰일지, 어떤 설정이 필요한지를 매번 생각하고 코드에 적용해야 했습니다. 또한 이러한 API 요청 코드 구조의 변화가 있을 경우, 각 API 요청 코드를 전부 찾아가 일일이 수정해주어야 했습니다. 뿐만아니라 각 개발자마다 다른 구현 방식으로 인해 코드의 일관성이 떨어졌고, 이는 가독성을 저해하는 요소였습니다.
정리해보자면 다음과 같은 문제점들이 있었습니다.
반복적인 코드
기본 URL 설정
헤더 설정
에러 처리
응답 파싱
일관성 부족
개발자마다 다른 구현 방식
에러 처리 방식의 차이
타입 처리의 비일관성
유지보수의 어려움
API 로직 변경 시 여러 곳에 전체적인 수정 필요
위와 같은 기본 fetcher의 단점을 극복하기 위해 우리 프로젝트에 Custom Fetcher를 만들었습니다.
if (endpoint === "/auth/token/verification") { return { status: response.status } as T; }
// 커스텀 에러 객체를 사용하여 일관된 에러 형식 제공 if (!response.ok) { const error = newError("API request failed") asFetcherError; error.status = response.status; error.message = `Server error: ${response.status}`; throw error; }
return response.json(); }
fetcher 함수에서는 타입스크립트 제네릭을 통해 응답 타입을 보장할 수 있도록 하였습니다. 또한 기본적인 설정에 사용자 설정을 병합하도록 하여 보다 유연하고 확장성있게 사용될 수 있도록 하였습니다. 뿐만아니라 Next.js SSR 환경을 고려한 토큰 처리도 해주었습니다.
특수케이스 처리
1 2 3 4 5 6 7
if (mergedConfig.bodyinstanceofFormData) { if (mergedConfig.headers) { delete mergedConfig.headers["Content-Type"]; } } elseif (mergedConfig.body) { mergedConfig.body = JSON.stringify(mergedConfig.body); }
우리 앱에서 기본적으로 사용되는 api 의 content type인 application/json이 아닌 회원가입, 여행 만들기 등에 활용되는 FormData 타입일 때 content type을 바꿔주도록 구성했습니다. FormData 처리를 위해 Content-Type을 자동으로 제거하였고, JSON 데이터를 자동으로 직렬화하도록 하였습니다.
처음 소개했던 기존 방식에 비해 훨씬 간결하고 가독성있게 API 요청 코드를 관리할 수 있게 되었습니다. API 설정 관련하여 고민하며 작성했던 기존 코드에 비해 중앙 집중화되어 관리되는 Custom Fetcher를 통해 실제 팀원들이 API 요청을 작성할 때에는 “메서드”, “엔드포인트”, “반환 타입”만 신경쓴다면 바로 쉽게 사용할 수 있었습니다.
▪︎ 마치며
Custom Fetcher는 단순한 HTTP 클라이언트를 넘어 애플리케이션의 데이터 통신 계층을 체계화합니다. 타입 안정성, 코드 재사용성, 유지보수성을 모두 고려한 설계로, 개발 생산성을 크게 향상시킬 수 있습니다. 특히 Next.js의 서버 컴포넌트와 미들웨어 환경에서도 원활하게 동작하도록 구현되어, 현대적인 웹 애플리케이션 개발에 매우 적합합니다.
웹 애플리케이션에서 데이터를 가져오는 방식은 크게 클라이언트 사이드 렌더링(CSR)과 서버 사이드 렌더링(SSR)으로 나눌 수 있습니다.
클라이언트 사이드 데이터 페칭의 경우, 브라우저가 JavaScript를 실행하여 데이터를 가져오기 때문에 초기 HTML은 비어있는 상태입니다. 사용자는 데이터가 로드되기 전까지 로딩 상태를 보게 되며, 검색 엔진은 초기 HTML에서 의미 있는 컨텐츠를 찾을 수 없습니다.
반면 서버 사이드 데이터 페칭은 서버에서 데이터를 미리 가져와 완성된 HTML을 생성합니다. 이는 사용자에게 더 빠른 초기 로드 경험을 제공하며, 검색 엔진이 컨텐츠를 즉시 크롤링할 수 있게 합니다.
▪︎ SEO에서 SSR의 장점
검색 엔진 최적화(SEO)에 있어서 SSR은 다음과 같은 핵심적인 이점을 제공합니다.
▫︎ 완성된 HTML 제공
검색 엔진 크롤러가 JavaScript 실행 없이도 모든 컨텐츠 접근 가능
메타 데이터와 구조화된 데이터를 초기 HTML에 포함 가능
▫︎ 빠른 초기 로드
Time to First Contentful Paint (FCP) 개선
사용자 경험 향상으로 인한 간접적 SEO 효과
▫︎ 신뢰성 있는 컨텐츠 제공
동적 데이터 로딩으로 인한 컨텐츠 누락 방지
일관된 컨텐츠 구조 제공
▪︎ 프로젝트 적용 (구현 예시)
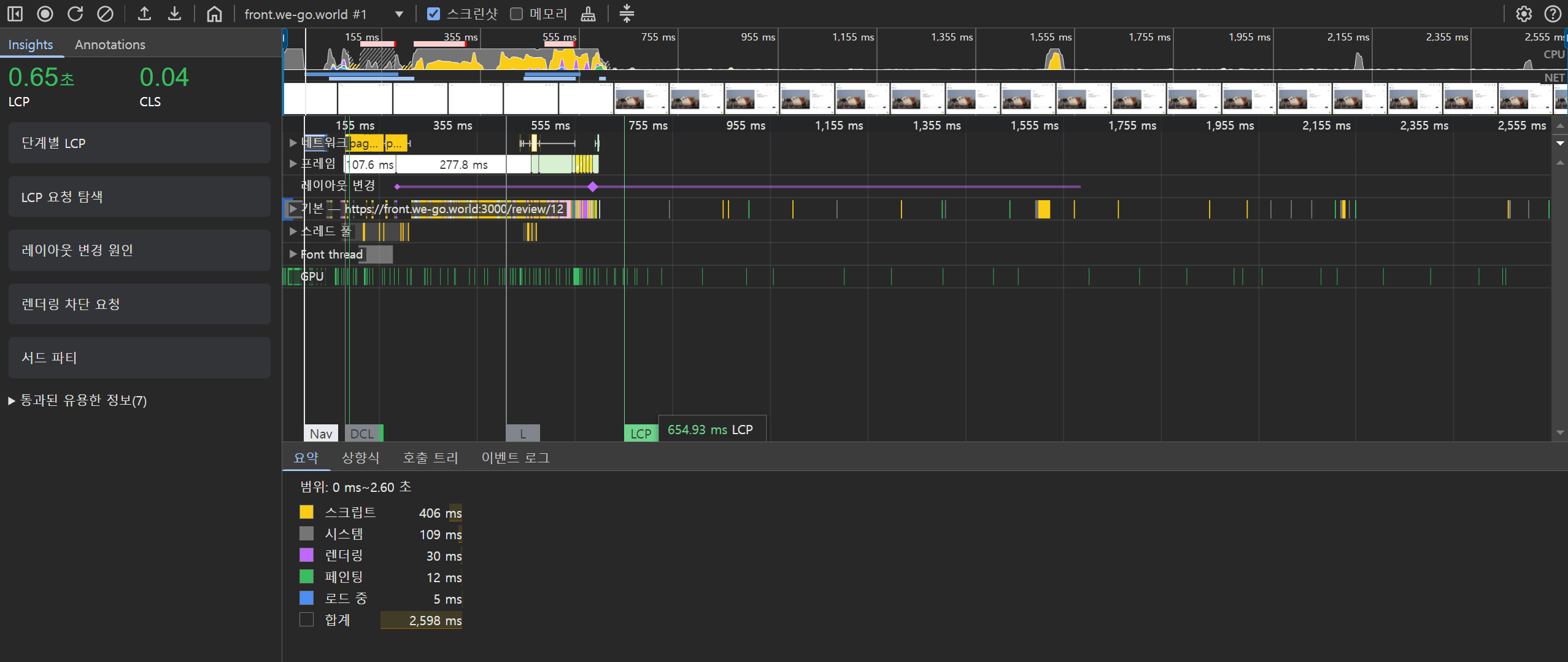
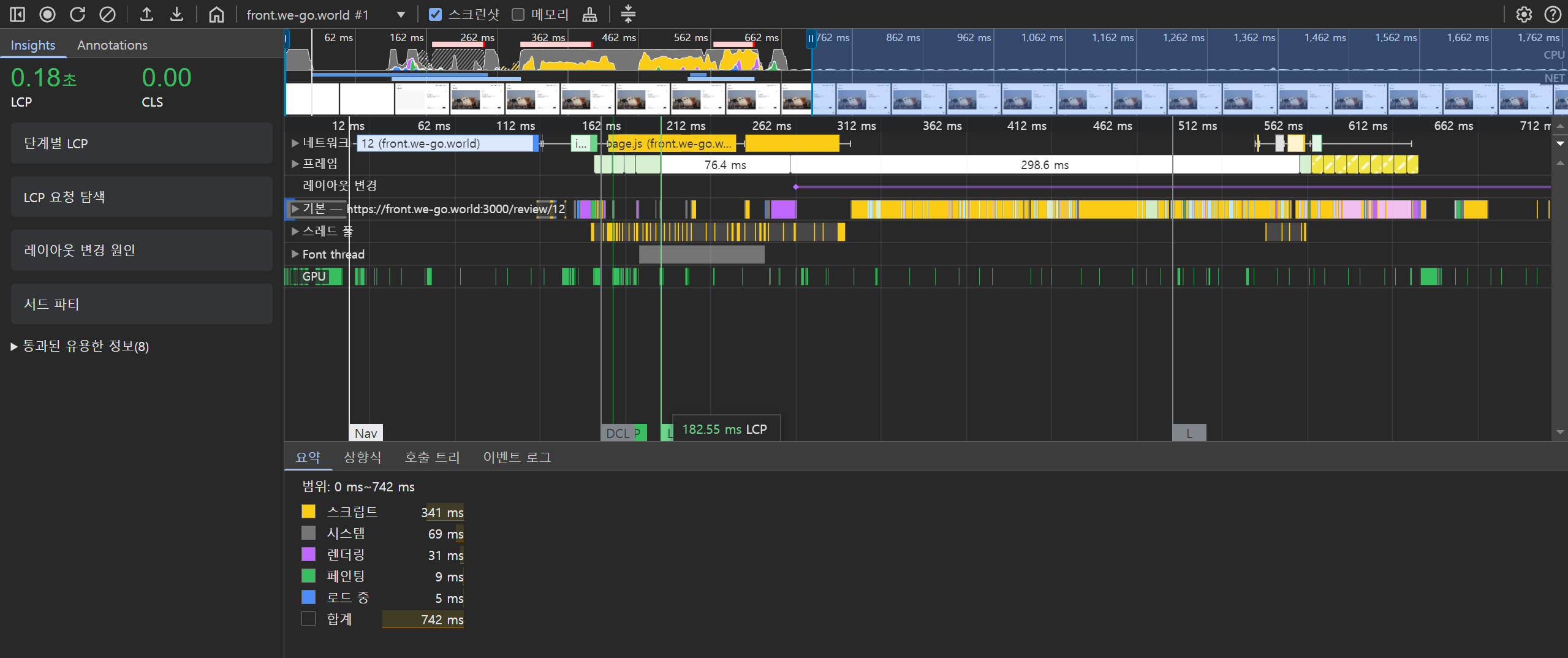
예시로 우리 프로젝트에서는 리뷰 상세 페이지에 SSR을 적용했습니다. 이 페이지는 정적인 정보를 주로 다루며 SEO가 중요한 페이지이기 때문입니다.
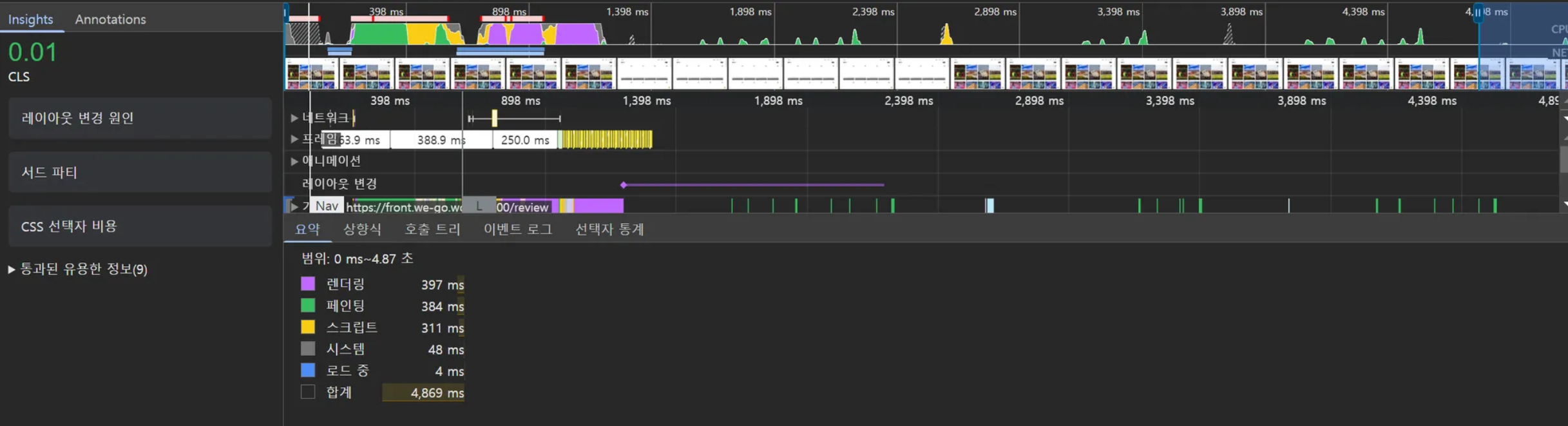
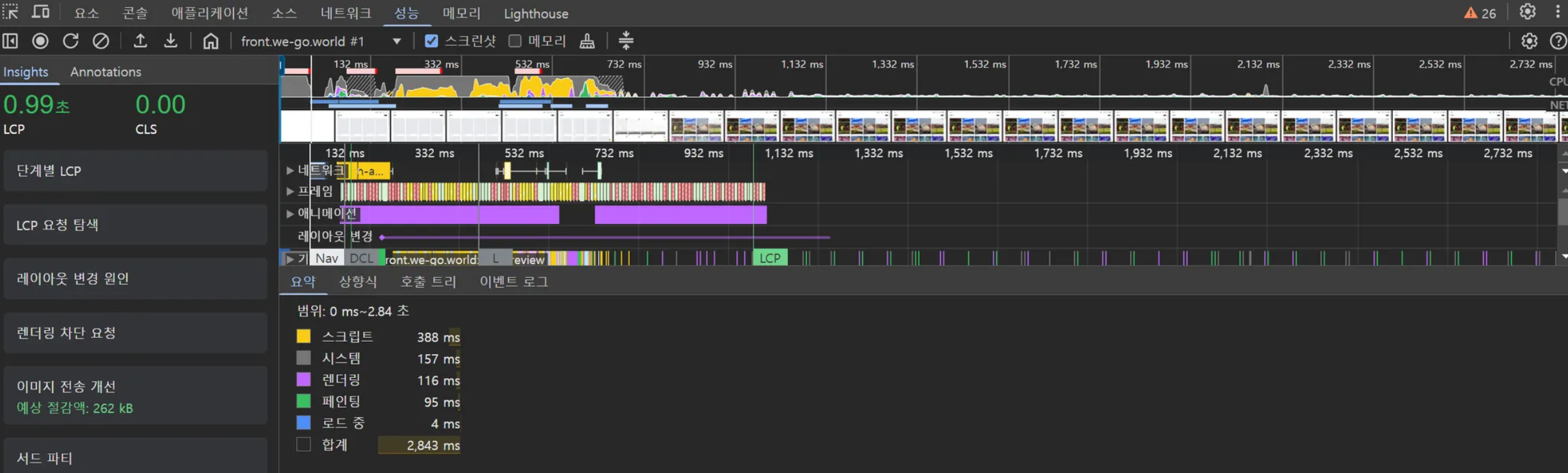
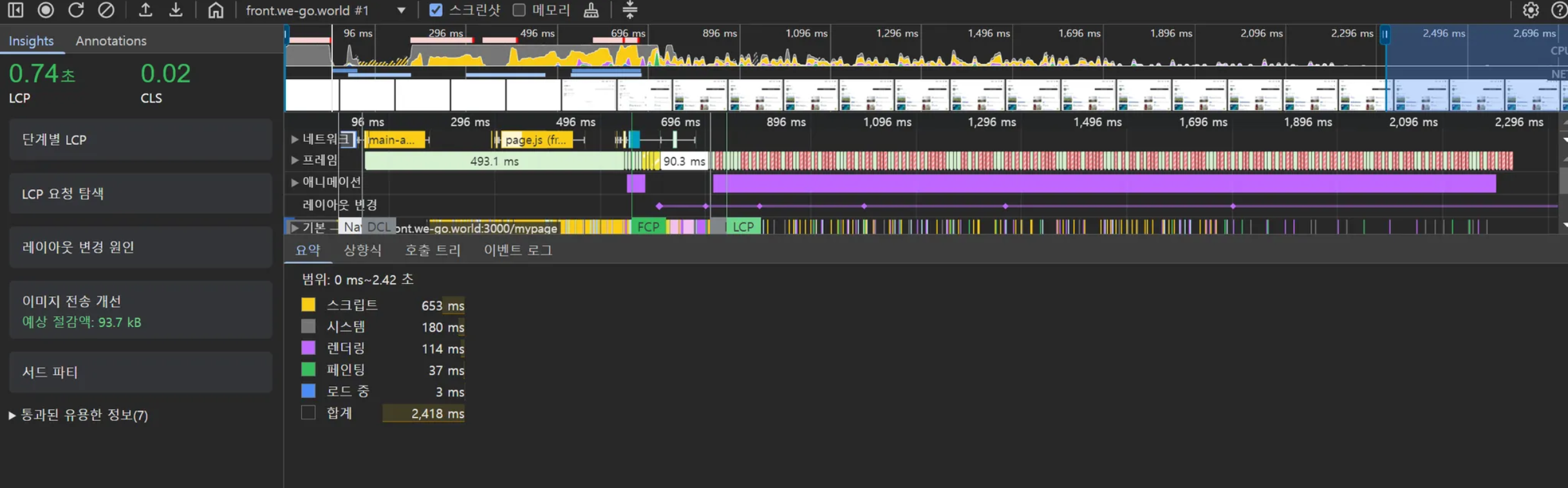
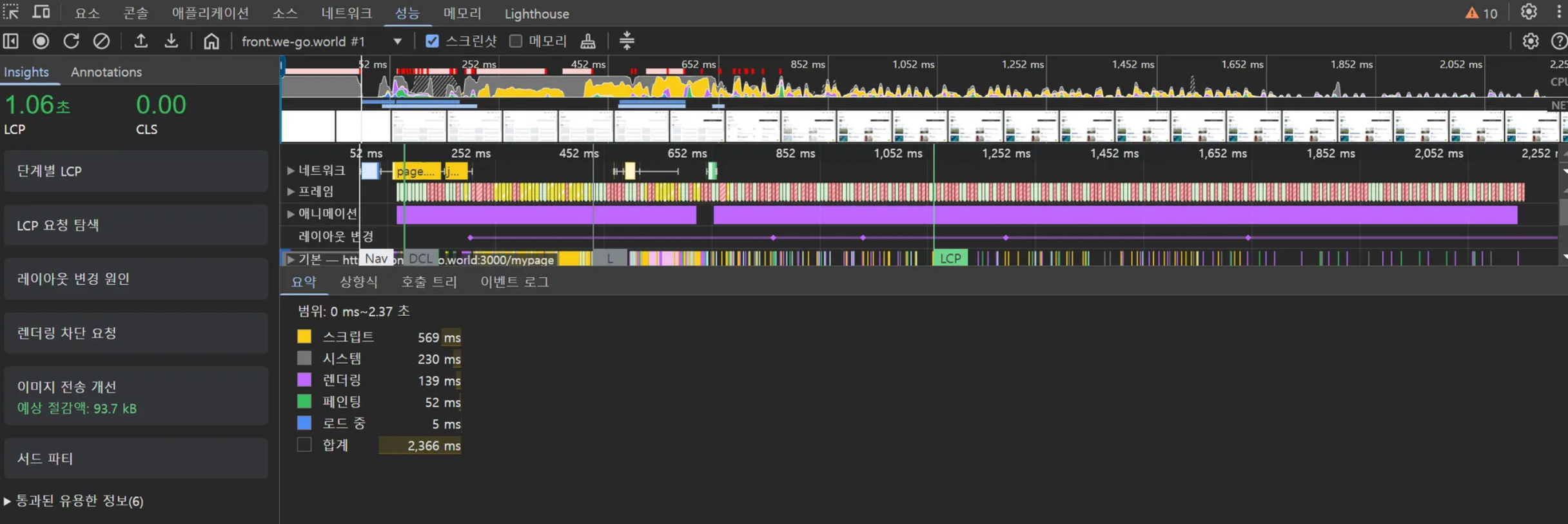
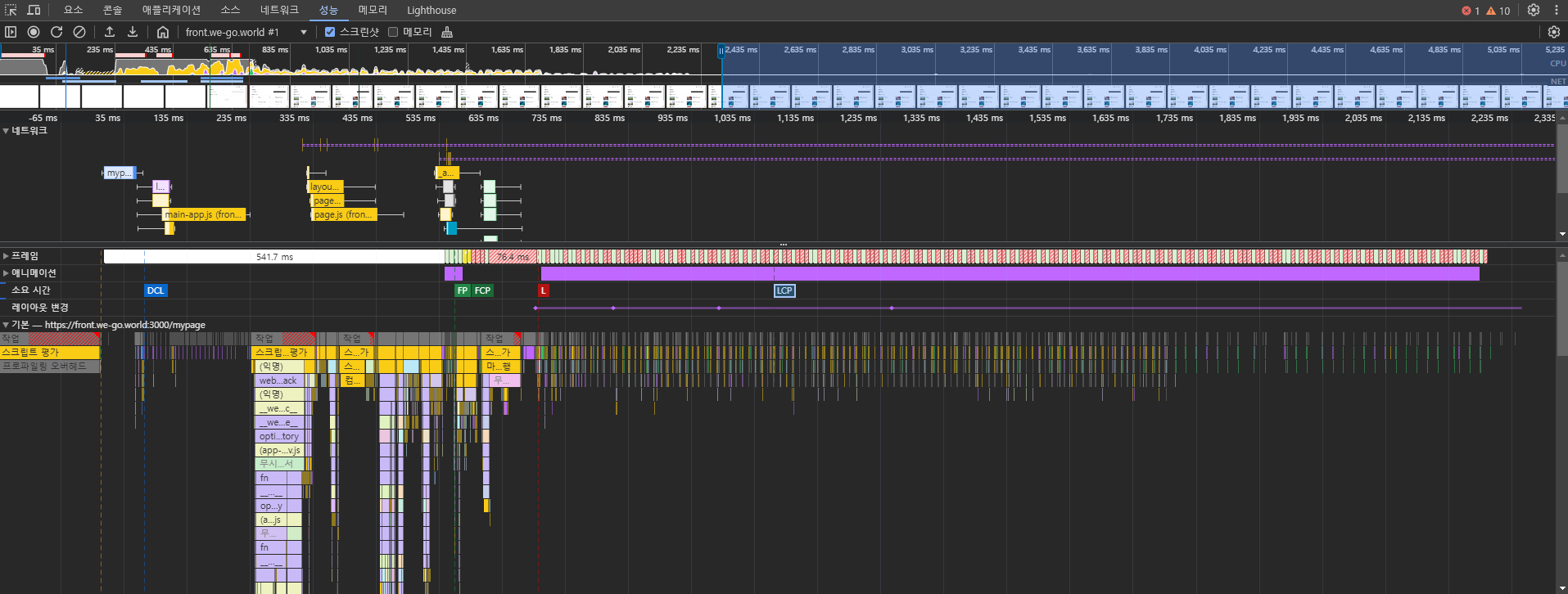
CLS(Cumulative Layout Shift)는 Google의 Core Web Vitals 중 하나로, 페이지 로딩 과정에서 발생하는 예기치 않은 레이아웃 이동을 측정하는 지표입니다. 쉽게 말해, 페이지가 얼마나 ‘덜컥거리는지’를 수치화한 것입니다.
1 2 3 4
[CLS 점수 기준] 좋음: 0.1 이하 개선 필요: 0.1 ~ 0.25 나쁨: 0.25 이상
CLS 수치가 점수 기준에서 합격점이라 할지라도 실제 페이지에서 유저가 경험할 때 부자연스러운 부분들이 있을 수 있습니다. WEGO 프로젝트에서 시프팅 현상으로 인한 부자연스로운 페이지 로딩의 예시를 살펴보고, 개선 방법들을 적용하여 실제 CLS 지표의 변화까지 살펴보겠습니다.
▪︎ 레이아웃 시프트가 사용자 경험에 미치는 영향
레이아웃 시프트는 다음과 같은 부정적인 영향을 미칩니다.
▫︎ 사용자 불편
읽고 있던 텍스트의 위치가 갑자기 변경
클릭하려던 버튼이 순간적으로 이동
스크롤 위치의 예상치 못한 변화
▫︎ 신뢰성 저하
웹사이트의 완성도가 떨어져 보임
전문성에 대한 의구심 유발
사용자의 재방문율 감소
▪︎ 프로젝트에서 발견된 CLS 이슈
▫︎ 스크롤바 시프팅
1 2 3 4 5
[문제 상황] 1. 초기 페이지 로드 시 데이터 없음 -> 스크롤바 없음 2. 데이터 로드 완료 -> 스크롤바 생성 3. 페이지 너비가 스크롤바 너비만큼 감소 4. 전체 레이아웃이 왼쪽으로 시프트
해결 방안 1) min-height
1 2 3 4
/* 항상 스크롤바 공간 확보 */ .page-container { min-height: 101dvh; /* 스크롤바가 항상 표시되도록 설정 */ }
간단하면서 효율적인 방식으로 해결하는 방법으로 min-height에 적정한 값을 주어 항상 스크롤이 존재하는 페이지로 보여주는 방법을 적용하였습니다.
해결 방안 2) Skeleton UI
1 2 3
... if (isLoading) return<ReviewSkeleton />; ...
데이터 페칭이 진행중일 때, 스크롤바가 생길 정도의 데이터만큼 스켈레톤 UI를 렌더링하여 스크롤바가 존재하도록 하였습니다.
위 두가지 방법을 통해 페이지 초기 로드 시부터 스크롤바 공간을 확보하여 레이아웃의 변화가 없도록 하였고 일관된 사용자 경험을 제공할 수 있었습니다.
개선 이후 측정 결과
▫︎ 이미지 시프팅
1 2 3 4 5 6 7
<Image src={travelImage} alt={`${travelName} - ${travelLocation} 여행 이미지`} width={300} height={300} className="h-full w-full rounded object-cover"// 이미지 로드 전후로 스타일 변경 />
이미지가 로드되면서 object-fit의 기본값에서 object-cover가 적용되는 과정이 화면에 보여지며 덜컥거리는 현상이 발생하였습니다.
해결방안
이를 해결하기 위해 Next.js Image 컴포넌트의 onLoadingComplete 속성을 적용하여 이미지가 완전 로드되기 전까지는 투명상태를 유지하고, 로드 완료 시 부드러운 페이드인 효과를 적용하였습니다.
개선 이후 측정 결과
▪︎ 개선 효과
사용자 경험 향상
부드러운 페이지 전환
예측 가능한 인터랙션
전문적인 웹사이트 인상
성능 지표 개선
CLS 점수 0.1 이하 달성
Core Web Vitals 전반적 향상
모바일 사용성 개선
비즈니스 효과
사용자 이탈률 감소
페이지 체류 시간 증가
전환율 향상 가능성
▪︎ 마치며
CLS 최적화는 단순한 성능 지표의 개선을 넘어 사용자 경험의 질적 향상을 가져옵니다. 특히 무한 스크롤이나 동적 이미지 로딩이 많은 현대 웹 애플리케이션에서는 필수적인 최적화 요소입니다. 우리 프로젝트에서 적용한 두 가지 해결 방안은 간단하면서도 효과적인 CLS 최적화 전략의 좋은 예시가 될 수 있습니다.
웹 애플리케이션에서 데이터 로딩은 피할 수 없는 과정입니다. 특히 네트워크 상태가 불안정하거나 대량의 데이터를 처리해야 하는 경우, 사용자는 빈 화면이나 로딩 스피너를 보며 기다려야 합니다. 이러한 대기 시간은 사용자 경험을 저하시키는 주요 요인이 됩니다. 이 문제를 해결하기 위해 저희는 스켈레톤 UI를 구현하여 적용했습니다.
▪︎ Skeleton UI 구현 과정
▫︎ 기본 스타일 설정
먼저 Tailwind 설정 파일에서 스켈레톤 UI의 기본 스타일을 정의했습니다. 스켈레톤 UI의 핵심은 로딩 상태를 시각적으로 표현하는 애니메이션입니다. 이를 위해 그라데이션 효과와 움직임을 결합했습니다.
사용자의 입력을 실시간으로 검증하는 기능을 구현할 때, 가장 먼저 고려해야 할 것은 성능과 메모리 관리입니다. 특히 이메일이나 비밀번호와 같은 입력 필드에서는 사용자가 타이핑하는 동안 지속적으로 유효성 검증이 발생하게 되는데, 이는 불필요한 연산과 메모리 사용을 초래할 수 있습니다. 이러한 문제를 해결하기 위해 debounce 기법을 활용한 최적화 방법을 소개하고자 합니다.
▪︎ Debounce를 활용한 최적화 구현
사용자가 입력 필드에 타이핑을 할 때마다 유효성 검증 함수가 실행되면 다음과 같은 문제가 발생할 수 있습니다:
불필요한 연산 발생: 사용자가 ‘example@gmail.com‘을 입력한다고 가정했을 때, 각 글자가 입력될 때마다 이메일 유효성 검증이 실행됩니다. 즉, ‘e’, ‘ex’, ‘exa’… 와 같이 완성되지 않은 상태에서도 검증이 수행되는 것입니다.
리소스 낭비: 특히 복잡한 유효성 검증 로직이나 API 호출이 포함된 경우, 불필요한 리소스 사용이 발생합니다.
메모리 누수 가능성: 컴포넌트가 언마운트되었을 때 진행 중이던 검증 작업들이 적절히 정리되지 않으면 메모리 누수로 이어질 수 있습니다.
이러한 문제를 해결하기 위해 lodash의 debounce 함수를 활용하여 다음과 같이 구현했습니다.
실제 화면에 그려질 컴포넌트입니다. 텍스트 하이라이팅 기능에 대해 어떻게 구현할지가 최대 고민거리였습니다.
위 이미지처럼 Title과 message 들 중 텍스트에 색상으로 하이라이트가 들어가 있는 경우가 있었습니다. 어떤 식으로 인자를 받아야 해당 부분을 구현할 수 있을까 고민하다 하이라이팅 할 텍스트의 시작점과 끝점에 대한 정보와 color 정보를 받아 구현하도록 하였습니다.
프로젝트를 진행하면서 버튼 컴포넌트와 같은 공통 컴포넌트를 설계할 때, 확장성과 재사용성을 최우선으로 고려했습니다. 이를 위해 cva, clsx, tailwind-merge라는 세 가지 라이브러리를 조합하여 사용했는데요, 이번 글에서는 각 라이브러리의 특징과 이들을 조합했을 때의 시너지에 대해 공유하고자 합니다.
▪︎ 각 라이브러리의 특징과 역할
▫︎ CVA (Class Variance Authority)
Class Variance Authority(CVA)는 컴포넌트의 다양한 스타일 변형(variants)을 타입 안전하게 관리할 수 있게 해주는 라이브러리입니다. 특히 Tailwind CSS와 함께 사용할 때 그 진가를 발휘하는데, 이는 미리 정의된 스타일 조합을 타입 시스템의 보호 아래 안전하게 사용할 수 있게 해줍니다.
다양한 입력 형식 지원: 문자열, 객체, 배열 등 어떤 형태로든 클래스명을 전달할 수 있습니다. 이는 다양한 상황에서 유연하게 클래스를 조합할 수 있게 해줍니다.
자동 정리: falsy 값(undefined, null, false 등)을 자동으로 필터링하여 깨끗한 클래스명 문자열을 생성합니다.
직관적인 문법: 복잡한 조건부 클래스 로직도 읽기 쉽고 이해하기 쉬운 형태로 작성할 수 있습니다.
▫︎ Tailwind Merge
Tailwind Merge는 Tailwind CSS를 사용할 때 발생할 수 있는 클래스 충돌 문제를 우아하게 해결해주는 라이브러리입니다. 특히 재사용 가능한 컴포넌트를 만들 때 매우 유용한데, 이는 기본 스타일과 커스텀 스타일이 충돌할 때 가장 마지막에 선언된 스타일을 우선적으로 적용하는 방식으로 동작합니다.
Tailwind Merge를 통해 해결할 수 있는 실제 문제 상황을 예시로 살펴보겠습니다.
1 2 3 4 5 6 7 8 9
// Tailwind Merge 없이 사용할 경우 <button className="px-4 py-2 text-sm text-blue-500 px-6"> // px-4와 px-6이 충돌, 브라우저 CSS 규칙에 따라 먼저 선언된 px-4가 적용됨 </button>
// Tailwind Merge 사용 <buttonclassName={twMerge("px-4py-2text-smtext-blue-500", "px-6")}> // 의도한 대로 px-6이 적용됨 </button>
Tailwind Merge는 다음과 같은 핵심적인 문제들을 해결합니다.
충돌 해결: 같은 속성을 가진 클래스들이 충돌할 때, 가장 마지막에 선언된 클래스를 우선적으로 적용합니다. 이는 CSS의 일반적인 캐스케이딩 규칙과도 일치하는 직관적인 동작입니다.
최적화: 중복되거나 불필요한 클래스들을 자동으로 제거하여 최종적으로 깔끔한 클래스 문자열을 생성합니다.
모든 Tailwind 규칙 지원: Tailwind CSS의 모든 유틸리티 클래스와 변형자(modifiers)를 완벽하게 이해하고 처리할 수 있습니다.
▪︎ 세 라이브러리를 조합한 유틸함수 활용
이 세 라이브러리를 조합하여 사용할 때 발생하는 시너지는 매우 강력합니다. 각각의 라이브러리가 가진 장점들이 서로를 보완하면서, 더욱 강력하고 유지보수하기 쉬운 컴포넌트 시스템을 구축할 수 있게 됩니다.
// 동적 스타일링이 필요한 경우 <Button fill="blue" size="modal" className={cn( "mt-4", isSpecial && "border-2 border-primary-normal", isPriority ? "shadow-lg" : "shadow-sm" )} label="확인" />
// 조건부 스타일링이 필요한 경우 <Button fill="white" size="default" classNameCondition={{ 'opacity-50cursor-not-allowed':isDisabled, 'shadow-md':isActive, 'ring-2ring-primary-normal':isFocused }} label="제출하기" disabled={isDisabled} />
활용 패턴에서는 다음과 같은 이점을 얻을 수 있습니다.
className을 통해 상황에 따른 추가적인 스타일을 적용할 수 있습니다.
classNameCondition을 사용하여 여러 조건에 따른 스타일 변화를 한 번에 관리할 수 있습니다.
기본 variants와 커스텀 스타일을 자연스럽게 조합할 수 있습니다.
▪︎ 유지보수와 확장
이러한 설계는 장기적인 관점에서 큰 이점을 제공합니다.
1. 새로운 디자인 요구사항 대응
새로운 variant를 추가하기 쉽습니다.
기존 스타일을 수정하더라도 타입 시스템이 변경이 필요한 곳을 알려줍니다.
2. 일관성 유지
모든 버튼이 동일한 스타일 시스템을 따르게 됩니다.
디자인 토큰의 변경이 용이합니다.
3. 팀 협업
명확한 사용 방법과 타입 지원으로 다른 개발자들도 쉽게 사용할 수 있습니다.
문서화가 용이합니다.
▪︎ 마치며
이번 글에서는 CVA, CLSX, Tailwind Merge를 조합하여 어떻게 확장 가능하고 유지보수하기 좋은 버튼 컴포넌트를 구현했는지 살펴보았습니다. 이러한 설계 방식을 통해 얻은 주요 이점들을 정리해보면 다음과 같습니다:
▫︎ 실제 프로젝트에서의 효과
개발 생산성 향상
타입 시스템의 지원으로 실수를 사전에 방지할 수 있었습니다.
자동 완성 기능으로 개발 속도가 크게 향상되었습니다.
반복적인 스타일링 코드 작성이 줄어들었습니다.
디자인 시스템 일관성 확보
중앙에서 관리되는 스타일 variants로 인해 일관된 UI를 유지할 수 있었습니다.
디자인 변경 사항을 쉽게 적용할 수 있었습니다.
새로운 디자인 요구사항에도 유연하게 대응할 수 있었습니다.
코드 품질 향상
타입 안전성으로 인해 런타임 에러가 감소했습니다.
스타일 관련 버그를 쉽게 추적하고 해결할 수 있었습니다.
코드베이스가 커져도 유지보수가 어렵지 않았습니다.
이러한 접근 방식은 단순히 스타일링 문제를 해결하는 것을 넘어서, 확장 가능하고 유지보수하기 좋은 컴포넌트 시스템을 구축하는 데 큰 도움이 되었습니다. 특히 팀 단위의 개발에서 일관성을 유지하면서도 유연한 확장이 가능한 구조를 만들 수 있었다는 점에서 큰 의미가 있었습니다.
웹 애플리케이션에서 인증된 사용자와 비인증 사용자에 대한 페이지 접근 제어는 매우 중요합니다. 특히 사용자 경험(UX)을 해치지 않으면서 안전하게 구현하는 것이 핵심인데요. 이번 글에서는 Next.js의 미들웨어를 활용해 어떻게 더 나은 인증 플로우를 구현했는지 공유하고자 합니다.
▪︎ 기존 인증 구현의 문제점
유저의 인증 여부를 판단하기 위해 token 검증만을 위한 api를 백엔드 측에 요청했습니다. 백엔드 측에서는 요청의 쿠키에서 accessToken을 읽어 그 검증 여부에 따라 결과를 반환해줬습니다. 우리 프론트에서는 인가 필요 페이지에서 그 결과가 성공이면 페이지를 보여주고, 실패면 로그인 페이지로 리다이렉트 시키는 로직이 필요했습니다.
처음에는 컴포넌트 내부에서 api 요청을 하고 그 결과에 따라 리다이렉트 여부를 결정했습니다. 그러나 이 경우 api 요청에 대한 결과를 받는 동안 잠깐동안 페이지의 레이아웃이 보여지는 플리킹 현상이 발생했습니다. 추가로 각 컴포넌트마다 토큰 인증에 따른 리다이렉트 로직을 작성해주어야 했습니다.
▫︎ 깜빡임 현상 (Flash of Unauthorized Content)
1 2 3 4 5 6 7 8 9 10 11
// 컴포넌트 내부에서 인증 체크 시 발생하는 문제 constProtectedPage = () => { useEffect(() => { // 인증 체크 후 리다이렉트 if (!isAuthenticated) { router.push("/login"); } }, []);
return<div>보호된 콘텐츠</div>; // 잠깐 보였다가 사라짐 };
▫︎ 중복 코드 발생
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
// 여러 서버 컴포넌트에서 반복되는 인증 체크 로직 exportdefaultasyncfunctionPage1() { const isAuthenticated = awaitcheckAuth(); if (!isAuthenticated) { redirect("/login"); } // ... }
// 토큰 유효성 검증이 필요한 페이지 처리 if ((Object.values(NEED_LOGIN_PATH) asstring[]).includes(request.nextUrl.pathname)) { if (verifyResponse.status === 200) { return response; }
// 로그인된 사용자가 접근하면 안 되는 페이지 처리 if ((Object.values(NEED_LOGOUT_PATH) asstring[]).includes(request.nextUrl.pathname)) { if (verifyResponse.status !== 200) { return response; }
// 쿠키의 토큰 존재 여부에 따라 적절한 응답 반환 returnnewResponse(JSON.stringify(hasAccessToken ? mock.success.body : mock.error.body), { status: hasAccessToken ? mock.success.status : mock.error.status, headers: { "Content-Type": "application/json" }, }); };
▫︎ 모킹 시스템의 주요 특징:
엔드포인트 기반 모킹: 각 엔드포인트별로 성공/실패 응답을 미리 정의합니다.
토큰 기반 응답: 쿠키의 토큰 존재 여부에 따라 다른 응답을 반환합니다.
유연한 확장: 새로운 엔드포인트 추가가 용이한 구조입니다.
폴백 메커니즘: 모킹되지 않은 엔드포인트는 실제 API를 호출합니다.
이러한 모킹 시스템의 장점:
개발 효율성: 백엔드 API 완성 전에도 프론트엔드 개발 진행 가능
안정성: 예측 가능한 응답으로 일관된 개발 환경 제공
디버깅 용이성: 인증 관련 문제 발생 시 빠른 원인 파악 가능
▪︎ 마치며
Next.js의 미들웨어를 활용한 인증 플로우 구현은 단순히 기능적인 요구사항을 충족시키는 것을 넘어, 사용자 경험과 코드 품질 모두를 개선하는 결과를 가져왔습니다. 특히 페이지 전환 시의 깜빡임 현상 제거와 인증 로직의 중앙 집중화는 프로젝트의 품질을 한 단계 높이는 중요한 요소가 되었습니다.
앞으로도 사용자 경험을 해치지 않으면서도 안전한 인증 시스템을 구축하기 위한 고민을 계속해 나갈 예정입니다.
expect(screen.getByText("여행에 대한 후기를 남겨주세요!")).toBeInTheDocument(); expect(screen.getByLabelText("최대 20자 입력 가능 textarea")).toBeInTheDocument(); expect(screen.getByPlaceholderText("여행 제목을 입력해 주세요.")).toBeInTheDocument(); expect(screen.getByLabelText("최대 100자 입력 가능 textarea")).toBeInTheDocument(); expect(screen.getByPlaceholderText("여행에 대한 다양한 후기를 공유해 주세요!")).toBeInTheDocument(); }); });