KMP 알고리즘 ) 문자열에서 특정한 문자열을 찾는 것을 O(N)으로 해결하기

부분문자열 찾기

위 이미지와 같은 문제에서 어떠한 문자열 내에서 특정한 다른 문자열을 찾을 때 가장 단순한 방법은 두 문자열의 각 문자들을 비교하는 것입니다. 그러나 이 경우 각 문자열의 모든 문자들을 매칭하여 탐색해야하기 때문에 효율성이 낮습니다. 따라서 대상 문자열의 크기가 크거나 효율성을 높이고 싶다면 KMP 알고리즘을 고려해볼 수 있습니다. 위 사진을 예시로하여 문자열을 찾는 두가지 방법에 대해 밑에서 알아보겠습니다.
▪︎ 두 문자열의 각 문자 비교
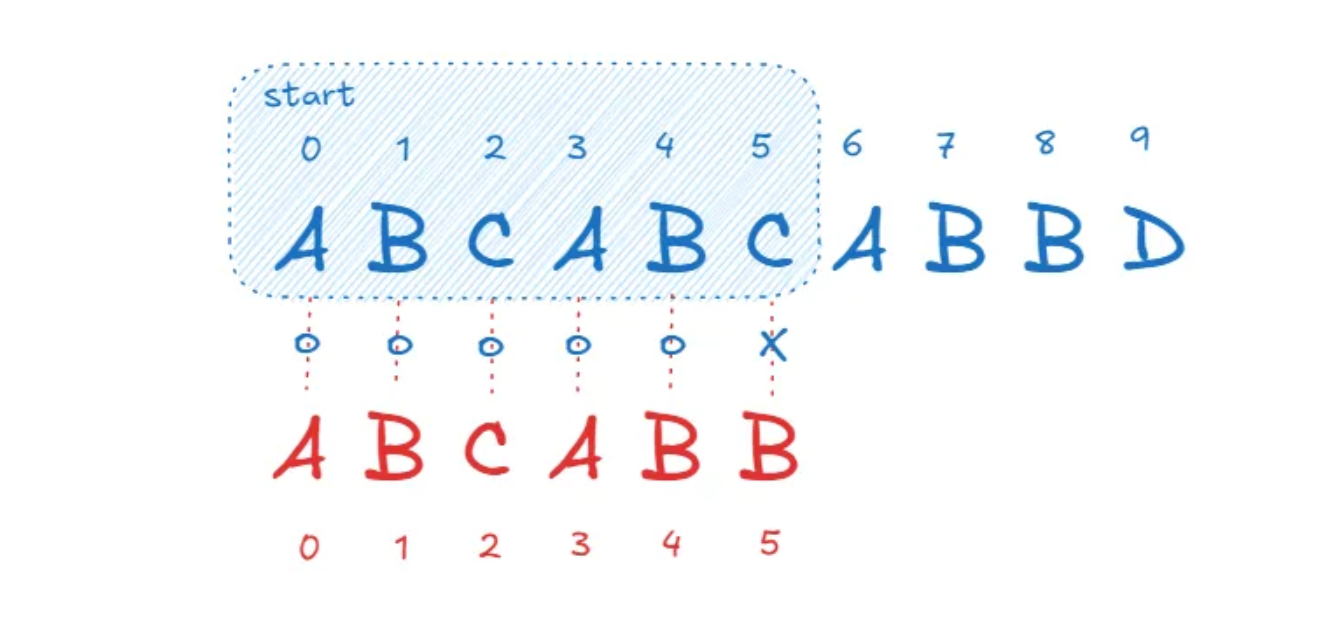
str을 기준으로 각 문자를 순회하되 해당 문자가 subStr의 첫 문자와 같다면 그 다음 문자들을 비교하는 방식으로 이루어집니다. 이 경우 str을 순회하는 start 포인터와 str과 subStr의 일치여부 확인을 위한 위치 포인터가 필요하기 때문에 O(NM)의 시간복잡도를 가집니다.
1 | const str = "ABCABCABBD"; |
▪︎ KMP 알고리즘
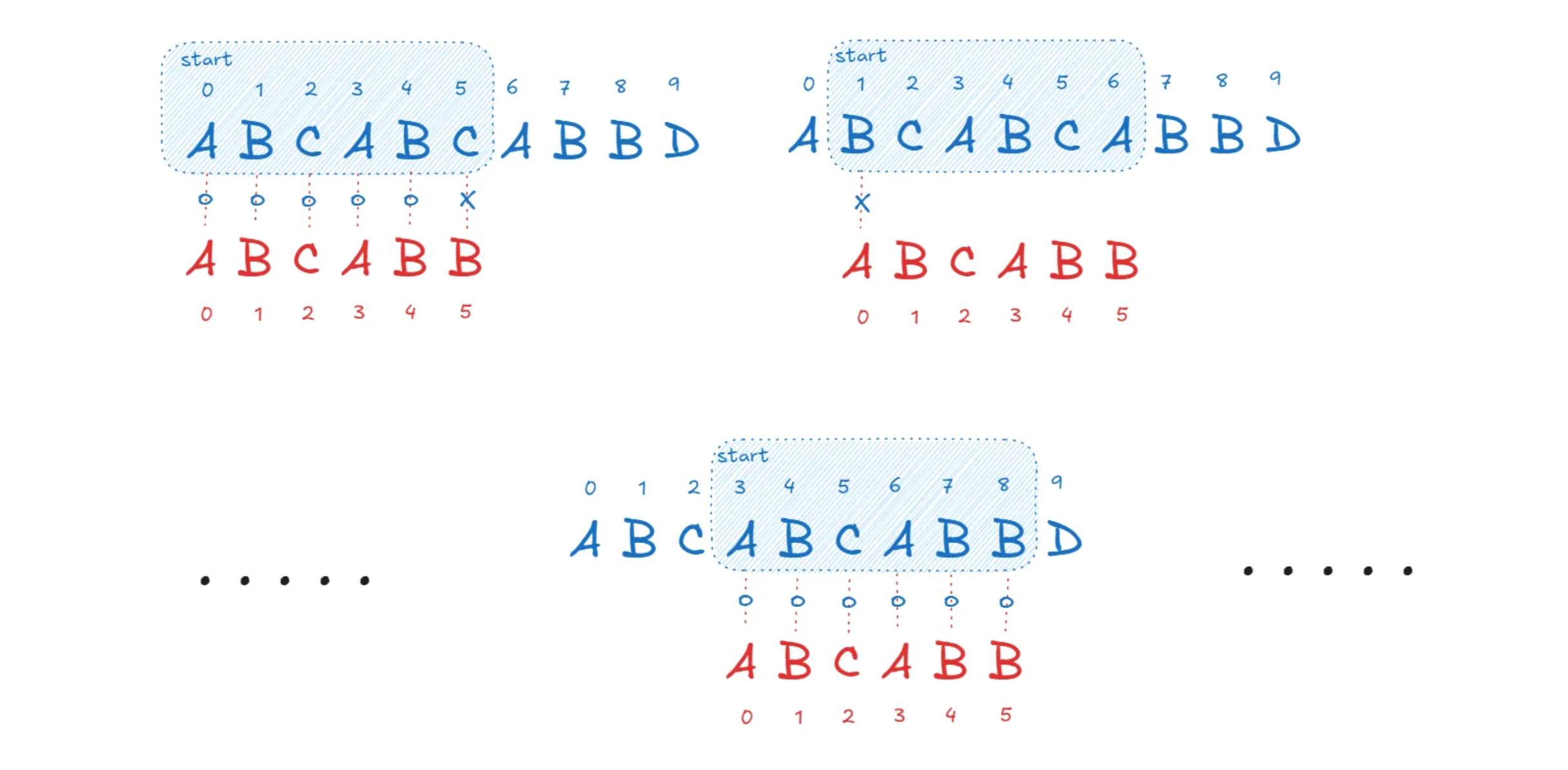
위 방법을 개선하여 효율성 높게 문자열을 찾는 방법이 KMP 알고리즘입니다. KMP 알고리즘은 무려 O(N+M)의 시간복잡도로 해결이 가능합니다. 어떻게 그것이 가능할까요? 문자열들의 각 문자들을 비교하는 방법에서는 버려지는 정보들을 활용하기 때문입니다. 위의 예시를 다시 가져와보겠습니다.
두 문자열을 비교하던 중 매칭이되지 않은 문자들을 만났습니다. 이 때 우리는 ABCABC가 ABCABB가 아니라는 것을 확인함과 동시에 ABCABB의 앞쪽 문자들과 매칭되는 부분(index 3 ~ 4)이 있다는 정보를 얻게되었습니다. 이 정보를 활용하면 str문자열의 각 문자를 시작으로 하는 문자열을 전부 확인하는 것이 아니라 subStr의 앞쪽 부분과 매칭되는 index 3에서부터 다시 비교를 시작할 수 있습니다.
이 원리를 이용하면 str을 이중 순회하는 것이 아닌 한번의 순회만으로 문자열을 찾아낼 수 있습니다. subStr을 문자열의 접두사이면서 접미사인 부분 문자열들에 대한 정보와 매칭하고 그 정보를 이용하여 str의 문자를 순회하는 동안 subStr의 포인터를 이동시켜 같은 문자열인지를 판단합니다.
KMP 알고리즘은 다음 단계를 통해 구현할 수 있습니다.
- subStr의 접두사,접미사 관련 정보를 담은 pi를 생성합니다.
- str을 순회하며 각 문자열의 pointer 이동합니다.
- subStr의 포인터가 끝으로 이동했을 때에 문자끼리 같다면 동일 문자열입니다.
▫︎ failure 함수를 통해 pi 배열 생성
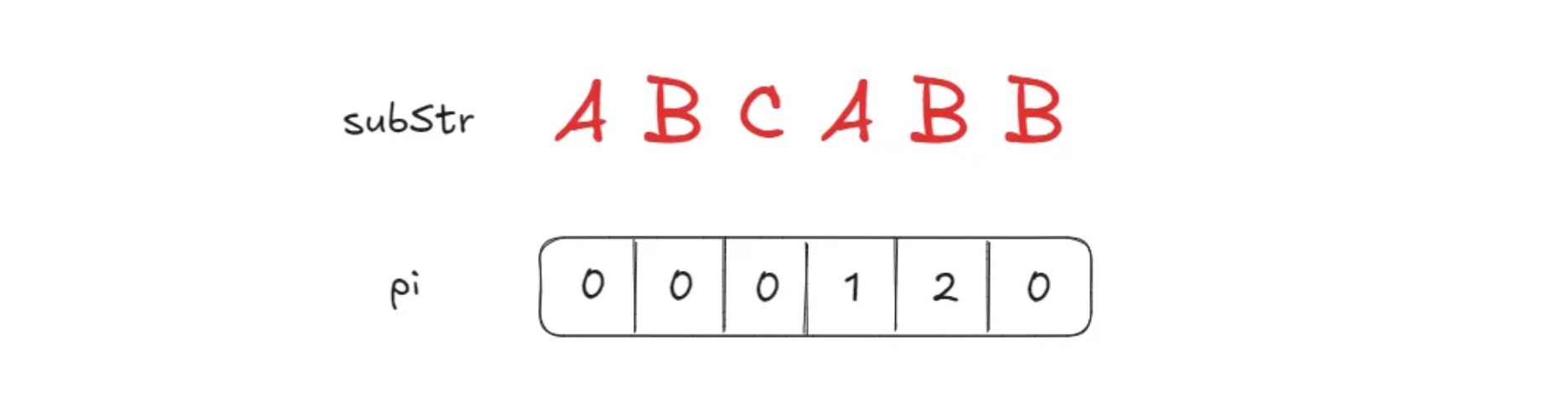
pi 배열은 subStr의 접두사와 접미사를 확인하여 같은 길이를 값으로 가지는 배열입니다. pi의 index 0은 0으로 시작하며 이후부터는 해당 인덱스까지의 부분문자열의 접두사와 접미사가 같은 길이를 값으로 가집니다. pi 배열은 failure함수를 통해 만들 수 있습니다.
“ABCA”의 경우 앞 뒤 “A”가 같기 때문에 1을 값으로 가집니다.
“ABCAB”의 경우 앞 뒤 “AB”가 같기 때문에 2를 값으로 가집니다.
failure 함수의 동작
- 첫 인덱스 값을 0으로하는 subStr 길이와 같은 배열을 생성합니다.
- 새로운 포인터 k를 선언하고 subStr을 순회하면서 다음 동작을 반복합니다.
- subStr[k]와 subStr[i]가 같은 경우 pi[i]에 k+1을 저장하고 k와 i 인덱스를 모두 증가시킵니다.
- 다를경우 k에 pi[k-1] 위치에 있는 값을 재할당합니다. (이 동작을 subStr[k]와 subStr[i]가 같아지거나 k가 0이 될 때까지 반복합니다) 이후 i 인덱스만 증가시킵니다.
1 | const subStr = "ABCABB"; |
▫︎ pi배열과 두 문자열을 이용해 문자열 찾기
이제 pi 배열을 이용해서 문자열을 찾아보겠습니다. str과 subStr의 각 포인터들을 이동시키면서 str을 순회합니다. 아래 그림과 같은 방식으로 동작합니다.

1 | const str = "ABCABCABBD"; |