WEGO 프로젝트의 개발 과정
UX/UI, BackEnd와 진행하는 협업 프로젝트에서 프로젝트 리더를 맡아 “모임”이라는 주제를 바탕으로 프로젝트를 진행하게 되었습니다. 이번 포스트에서는 WEGO를 개발하게 된 배경과 팀구성, 프로젝트 구조까지 WEGO를 개발하면서 진행된 프로세스들을 자세하게 풀어보겠습니다.
▪︎ 프로젝트 개요
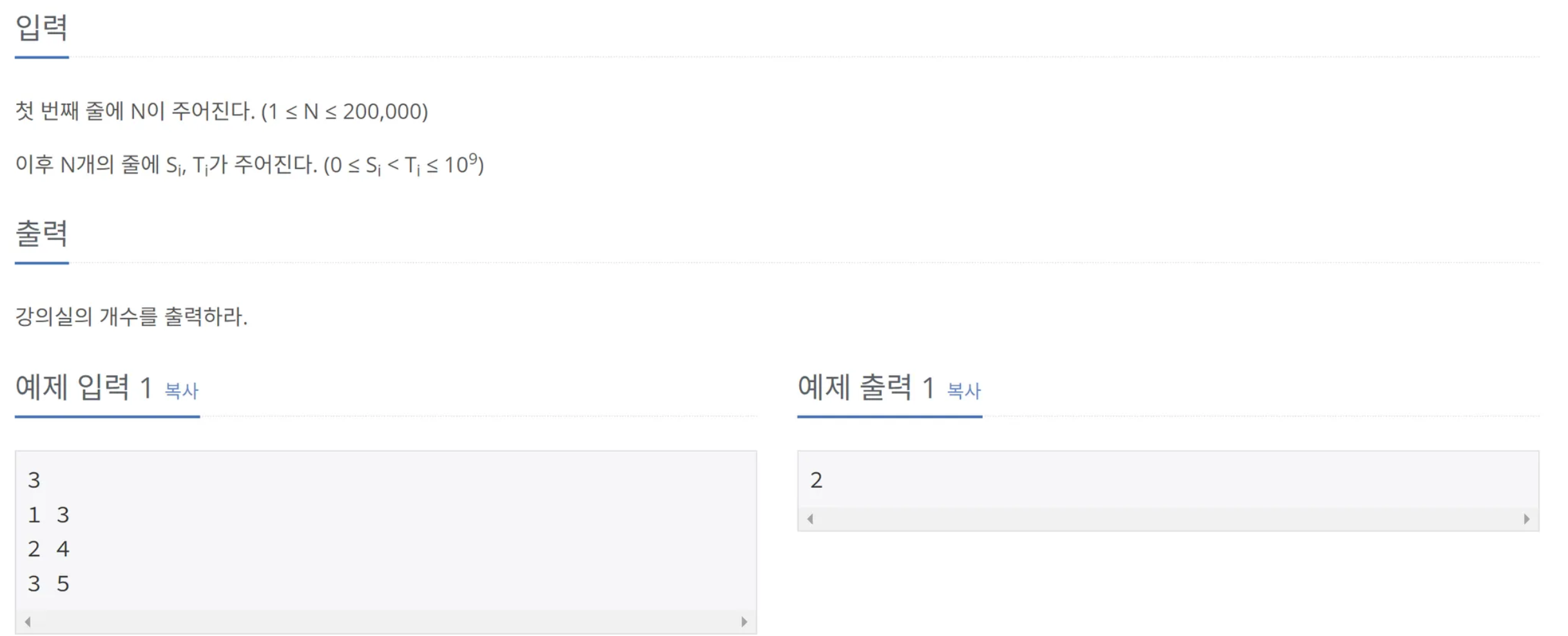
▫︎ 팀 구성
UX / UI : 1명
FrontEnd : 3명
BackEnd : 2명
▫︎ 사용 기술
Typescript, Next.js, Tailwind CSS, Zustand, Tanstack Query, MSW, Jest, Storybook
▫︎ MVP 개발 기간
2024.11.25 - 2025.01.06
▪︎ 프로젝트 배경
▫︎ 프로젝트의 시작
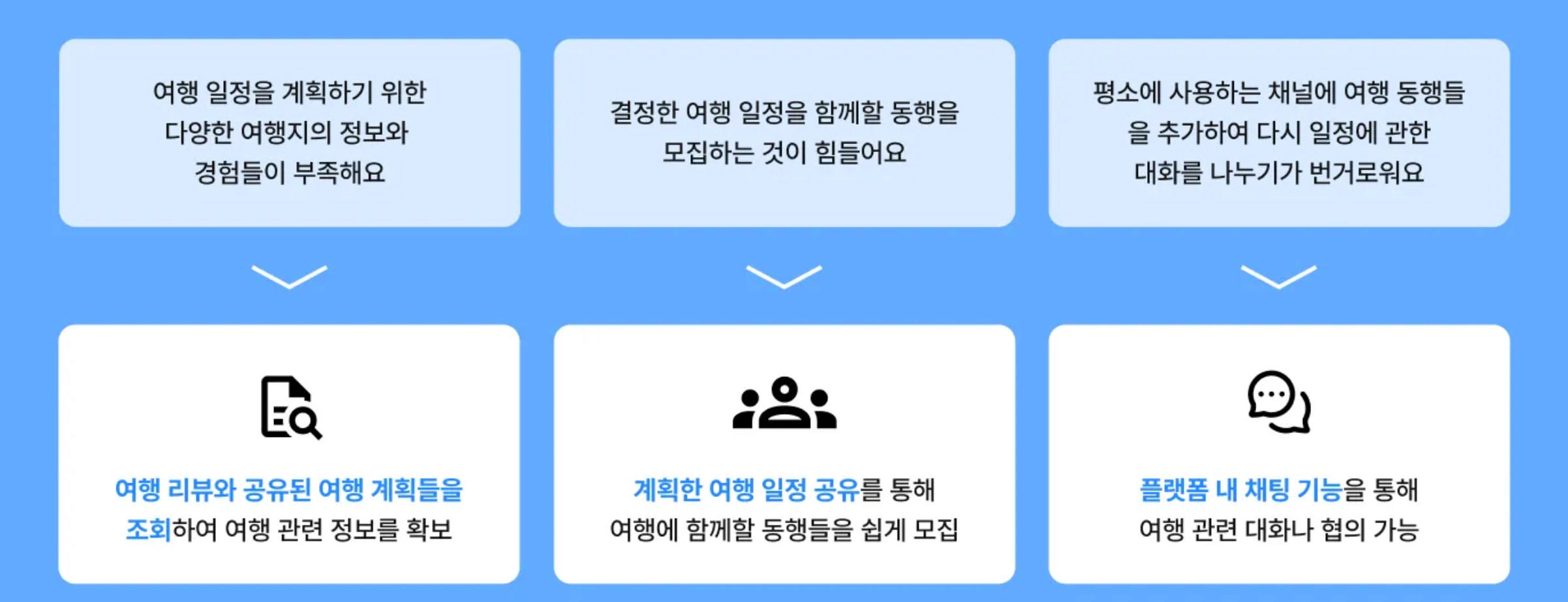
우선 “모임”이라는 주제를 구체화 했습니다. 기존에 사람들이 가지고 있던 에로사항이나 있었으면 하는 기능들을 서비스로 만들고 싶었습니다. 다양한 키워드를 모임에 대입해가며 고민한 결과, 사람들이 여행을 시작하는데 있어서 어려움을 겪고 있다는 점을 파악했습니다. 지인들을 통한 QA를 바탕으로 페르소나와 키피쳐를 정의하고 서비스 제작을 시작했습니다.
QA의 공통적인 사항들을 정리해보았을 때, 아래와 같은 에로사항이 있다는 것을 확인했습니다. 문제에 대해 서비스 기능을 이용하여 해결할 수 있도록 기획의 방향을 잡았습니다.

▫︎ 주제 선정
위와 같은 QA 결과를 바탕으로 저희는 “여행 동행 모집을 위한 플랫폼”이라는 주제로 개발을 시작하였습니다. 정리한 문제 상황들에 대한 해결 방법을 기능으로 정의하였습니다.
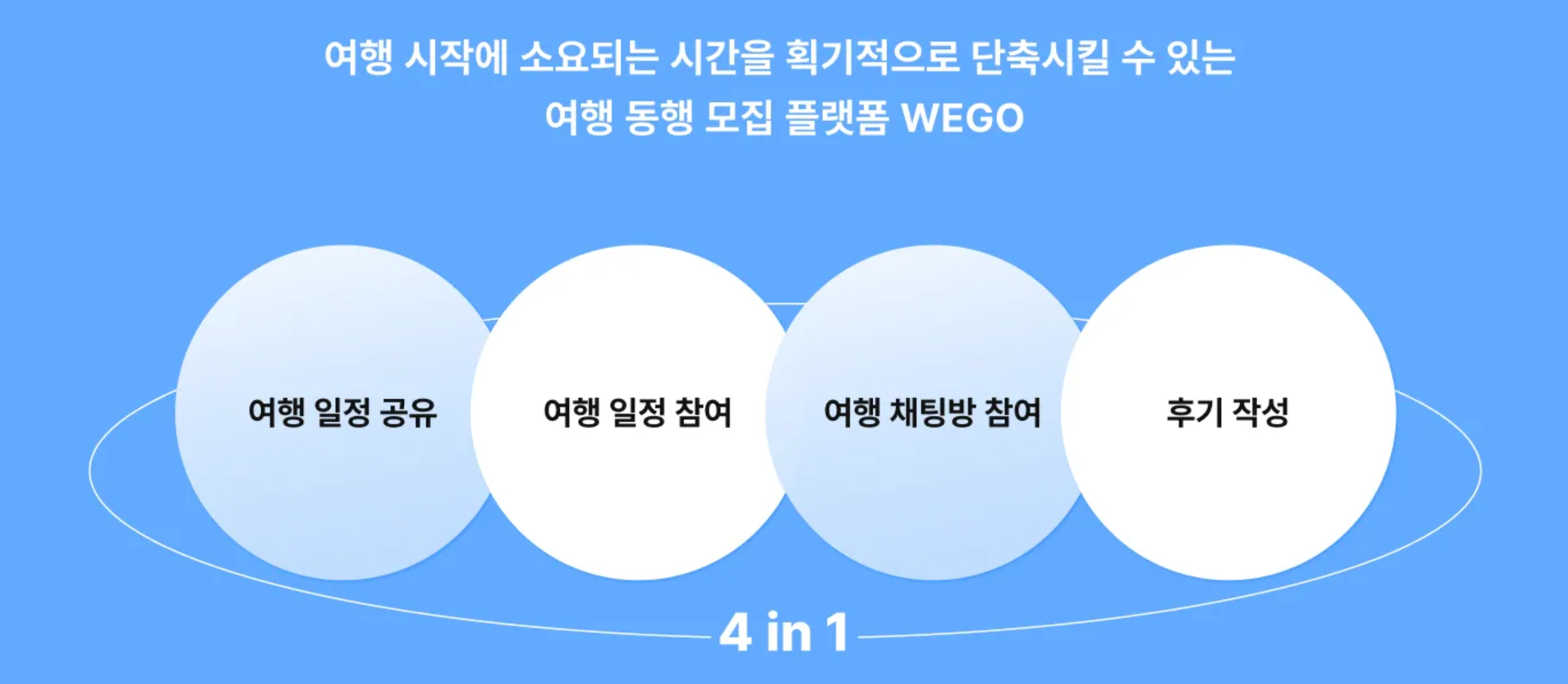
- 여행 리뷰와 여행 일정의 공유를 통해 여행지 정보 습득의 어려움이 있는 유저들의 불편을 해소하고자 하였고,
- 계획한 여행 일정 공유와 동행모집, 또 여행 일정 참가 기능을 통해 여행 동반인을 모으기 힘들어하는 유저들의 에로사항을 해결하고자 했습니다.
- 여행에 대한 이야기를 하기 위해 외부 채널들을 사용해야하는 번거로움을 해소하기 위해 플랫폼 내 채팅 기능을 도입했습니다.
WEGO는 여행 일정 공유와 참여, 동행모집 그리고 채팅방 참여를 통한 일행들과의 대화를 통해 여행 시작에 소요되는 시간을 획기적으로 단축시킬 수 있는 플랫폼으로 기획되었습니다. 추가로 여행 일정을 제시한 사람에 대한 신뢰도를 제공하기 위하여 각 여행에 대한 리뷰 기능또한 포함하게 되었습니다.
▪︎ 개발 프로세스
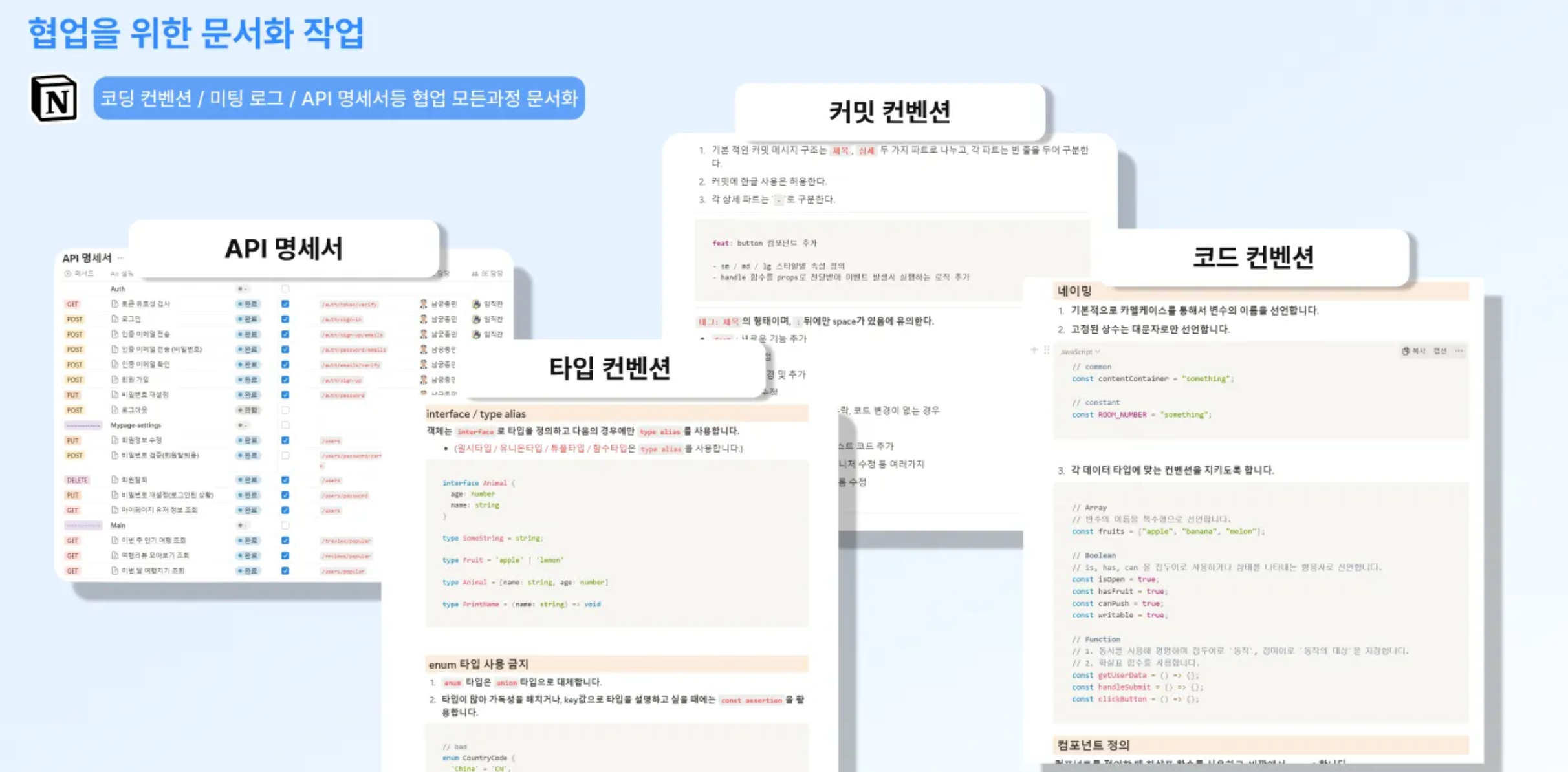
▫︎ 문서화
각 팀원들이 개발 진행 사항 및 개발에 관련한 컨벤션 등의 정보를 쉽게 파악할 수 있도록 노션을 통해 개발 과정을 문서화했습니다. API 명세서를 통해 구현 API에 대한 정보를 확인하고 백엔드와 댓글 기능을 통해 소통할 수 있도록 했으며, 타입,커밋,코드 등의 컨벤션을 정의하여 프로젝트 전체적으로 일관된 코드 스타일로 개발을 진행할 수 있도록 하였습니다.
▫︎ 와이어프레임 작성
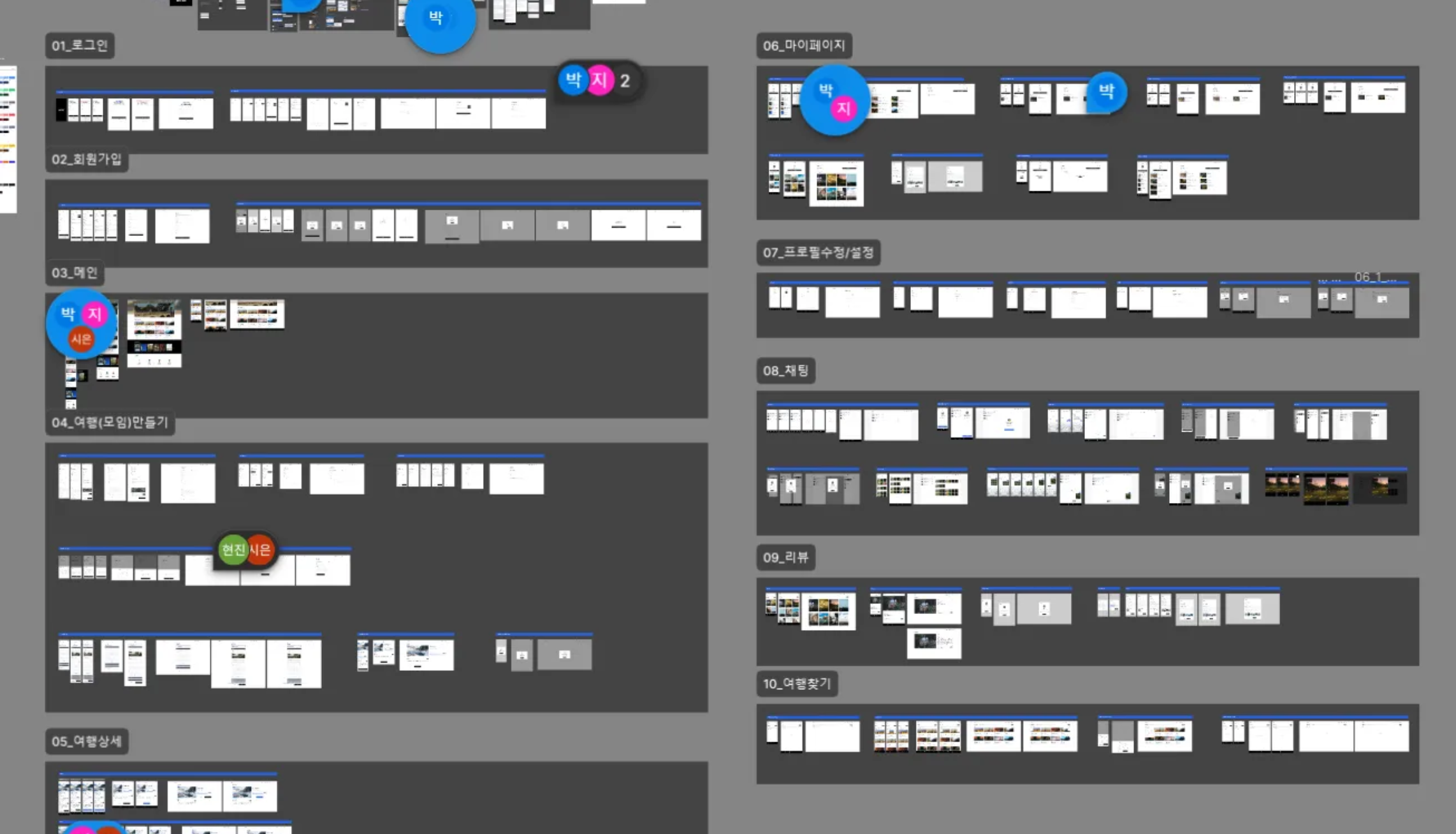
기획한 내용을 바탕으로 UX/UI 팀원의 빠른 진행을 위해 각 페이지에 필요한 정보들을 전달하기 위한 와이어 프레임을 작성하였습니다. 최대한 러프하게 구성하여 디자인의 자유도는 올리면서도 필수적으로 들어가야하는 정보들을 최대한 정리하고 깔끔하게 구성하여 디자인 팀에게 전달했습니다.

▫︎ 디자인 작업 & API 명세서 작성
전달받은 와이어프레임을 바탕으로 디자인 팀에서는 디자인 시스템과 반응형 화면 등의 작업을 시작했으며, 디자인 작업과 동시에 디자인과 와이어프레임을 바탕으로 프론트엔드와 백엔드 팀에서는 필요한 API에 대해 고민하고 명세를 작성하였습니다.

▫︎ CI/CD 파이프라인 구축
Git Hooks를 통한 로컬 환경 품질 관리
Husky를 활용하여 Git Hooks를 설정하였습니다.
1 | # .husky/pre-commit |
커밋 이전에는 코드 스타일 검사, 탕입스크립트 타입 체크, 린트 규칙 준수 여부를 확인하였고, 커밋 메시지 컨벤션을 검사하였으며, 푸시 전에는 단위 테스트를 실행하고 통합 테스트를 검증하여 빌드의 오류를 사전 방지했습니다.
Github Actions를 활용한 CI 파이프라인
1 | # .github/workflows/git-pr.yml |
- PR 생성 시 자동화 검증을 통해 빌드 오류를 차단했습니다. 다음 작업들이 PR 생성 시 자동으로 실행됩니다.
- 타입스크립트 타입 검사
- ESLint를 통한 코드 품질 검사
- 프로젝트 빌드 테스트
- 테스트 코드 실행
1 | # .github/workflows/storybook.yml |
- 추가로 Storybook의 변경사항을 자동으로 Chromatic에 배포하고 PR 코멘트로 프리뷰 URL을 제공하도록 하였습니다.
CD 파이프라인 구성
1 | # .github/workflows/git-push.yml |
메인 브랜치 푸시 시 자동으로 배포할 수 있도록 설정했습니다. 배포용 저장소로 코드를 동기화하여 Vercel 플랫폼을 통해 자동으로 배포될 수 있도록 하였습니다.
결과
CI/CD 파이프라인 구축을 통해 자동화된 코드 검사와 일관된 코드 스타일을 유지함으로써 코드의 품질을 향상시켰고, 반복 작업을 자동화함으로써 개발 생산성을 증가시켰습니다. 또한 표준화된 작업 프로세스로 협업 효율성 또한 개선되었습니다.
▫︎ 개발 업무 분배
개발 업무 분배는 초기에 나누어 진행하기 보다는 초기 개발 환경 설정 이후에 서비스 구성에 필요한 페이지, 기능들을 깃헙 이슈에 정리해두고 자신이 맡은 기능을 완료한 팀원이 asign 해가면서 아직 할당되지 않은 기능들을 팀원들이 가져가서 개발하는 방식으로 진행되었습니다.
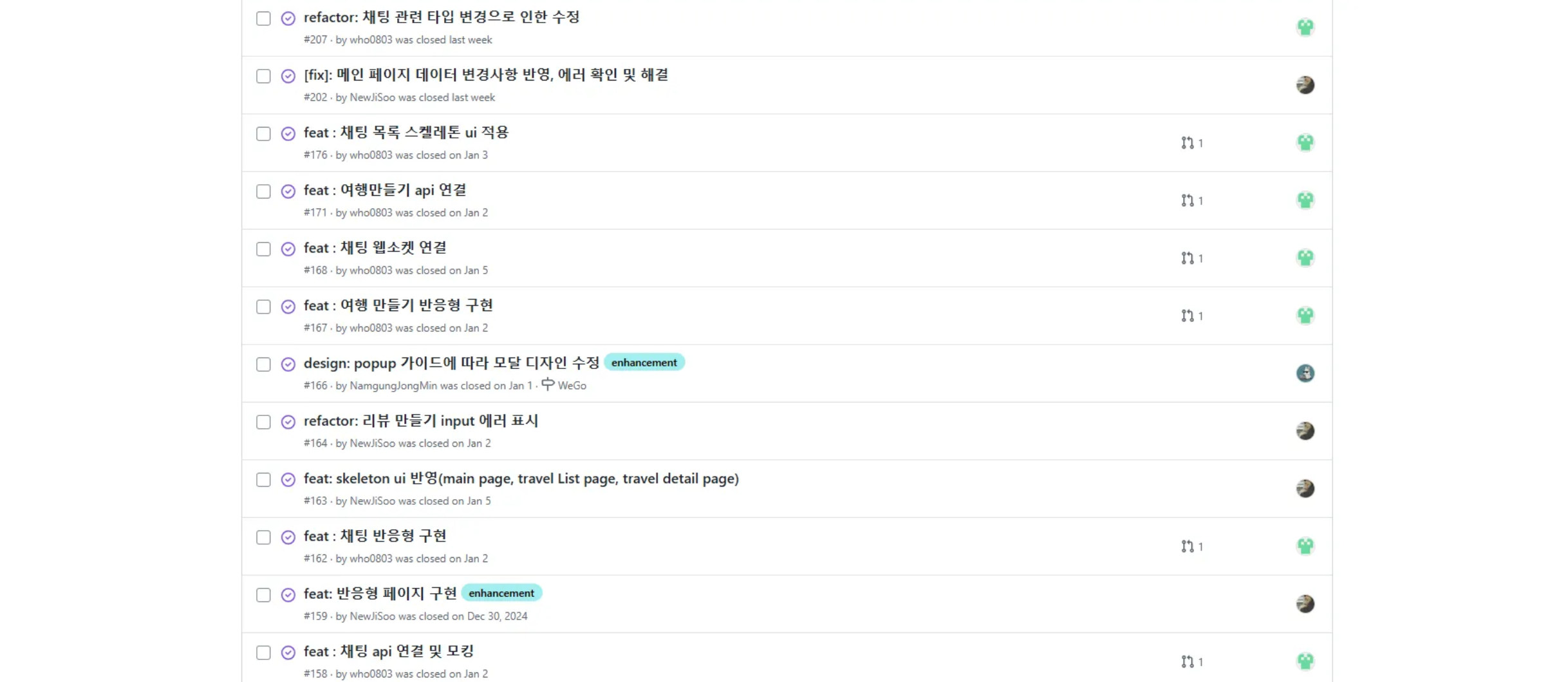
이를 통해 전체적인 개발의 진행이 빠르게 이루어졌고, 정해진 개발 기간 동안 정의한 기능들을 모두 개발 완료할 수 있었습니다.
▫︎ 개발 진행
디자인이 완성되는 대로 프론트엔드와 백엔드 팀에서는 개발을 동시에 진행했는데요, 처음에는 Bottom Up 방식으로 진행하는 것을 의도했지만 짧은 MVP 개발 기간동안 디자인 작업과 개발이 함께 이루어진다는점, 빈번한 기획 수정이 예상된다는 점으로 인해 완전한 아토믹한 요소들을 바탕으로 컴포넌트들을 쌓아올려가며 개발하는 방식을 적용하는 것이 어렵다는 결론에 도달하였습니다.
따라서 코드의 작성 또한 디자인과 기획의 변경에 대응하기 위해 확장성있고 유연한 방식으로 할 수 있도록 노력했습니다. 공통 컴포넌트들에 추가적인 ClassName과 ClassNameCondition이라는 Prop을 받아 사용하는 쪽에서 디자인의 변화를 대응할 수 있게 하였으며, 우선적으로 모든 기능을 개발하고 이후 리팩토링 과정에서 정돈하는 것으로 방향을 잡았습니다.
1 | const Button = forwardRef<HTMLButtonElement, Props>( |
템플릿 코드 작성
짧은 개발 기간을 효율적으로 사용하고 개발 생산성을 올리기 위해 많은 고민을 했습니다. 팀원들에 경우 결정된 기술을 사용해보지 못한 팀원들도 있었고, 있다 하더라도 이해도가 차이가 났습니다. 또한 각 기술들을 통해 작성하는 코드들이 일관되지 못할 것이라는 걱정도 있었습니다.
이를 해결하기 위해 미팅 때 기술에 대한 전체적인 이해도를 맞추기 위한 기술 발표를 진행했고, 템플릿 코드를 개발 이전 우선적으로 작성하여 코드 작성에 대한 가이드라인을 제시했습니다.
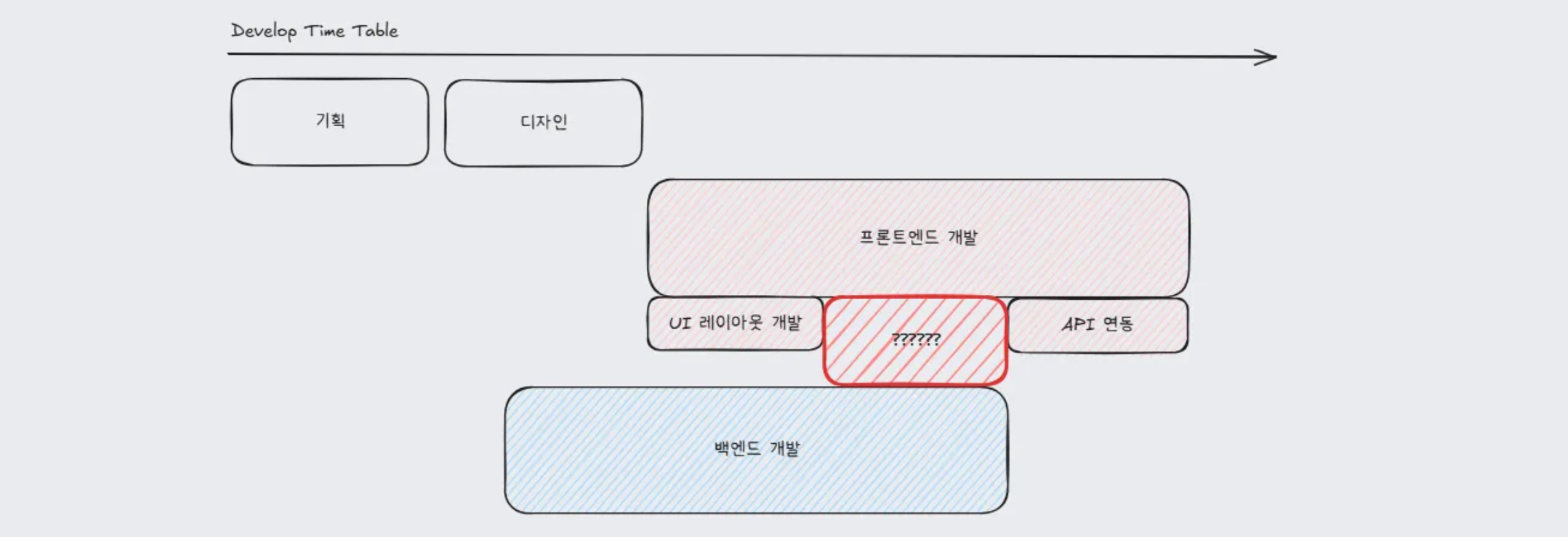
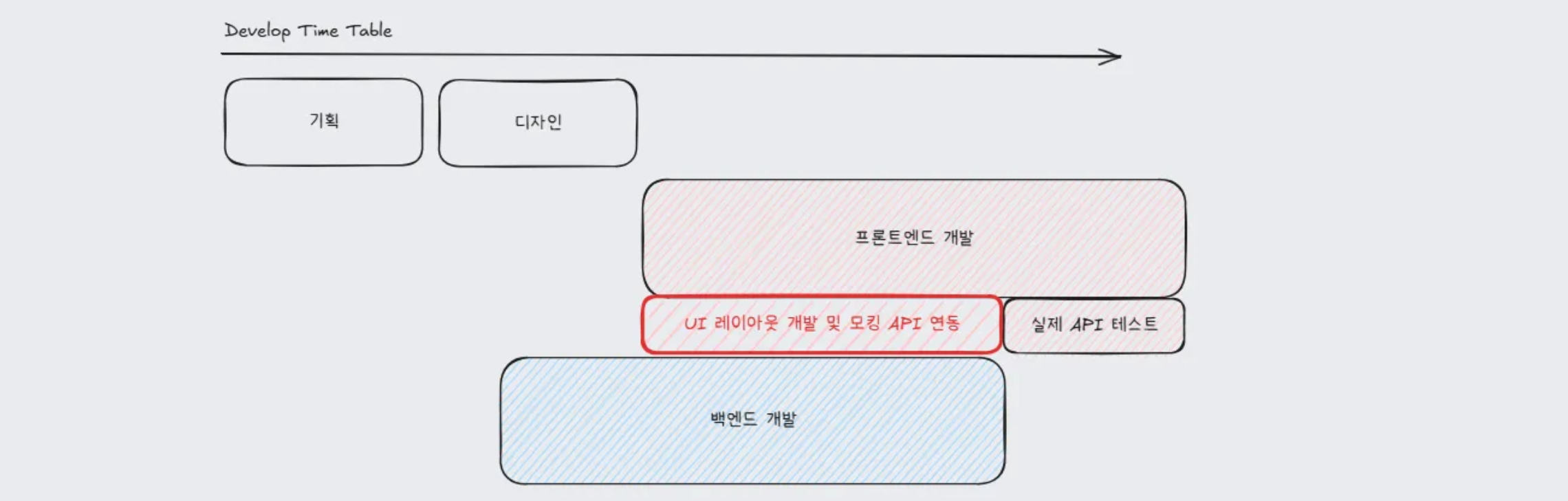
모킹 API 활용
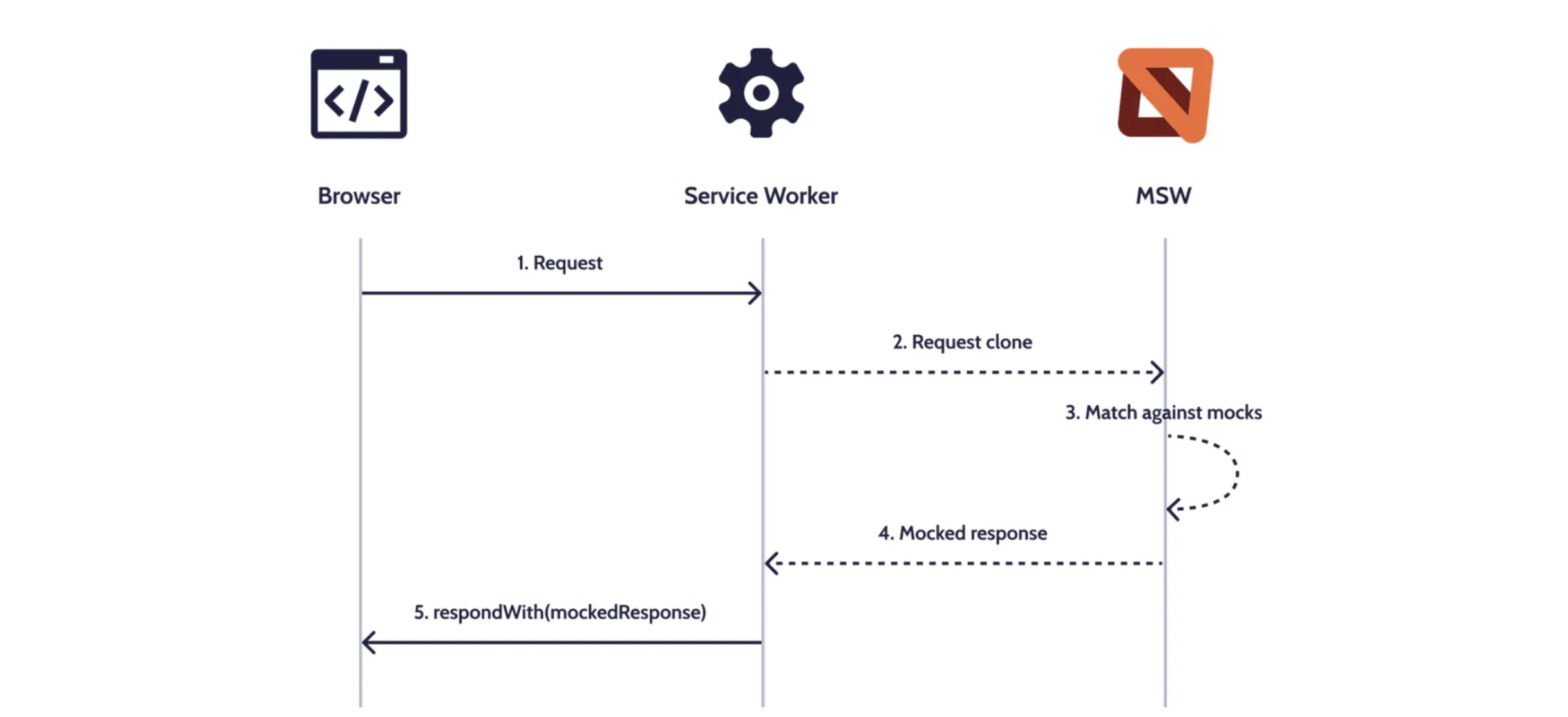
프론트엔드와 백엔드가 동시에 개발을 진행하는 경우 백엔드 개발 완료 이전 프론트엔드에서 API 관련 코드를 작성할 수 없다는 딜레마가 생겼습니다. 이를 해결하기위해 MSW의 API 모킹 기능을 활용하여 API 명세서를 바탕으로 API 관련 코드 작성을 진행했습니다.
프론트엔드에서는 모킹 API를 활용한 개발 환경과 실제 개발 완료된 API를 활용한 개발 환경을 나누어 테스트 할 수 있도록 세팅했고, 이를 통해 개발 생산성을 높일 수 있었으며, 백엔드 개발이 완료된 이후에도 브라우저에서 에러 상황을 연출할 필요 없이 모킹된 API를 통해 다양한 에러 상황들에 대해 테스트 해볼 수 있었습니다.
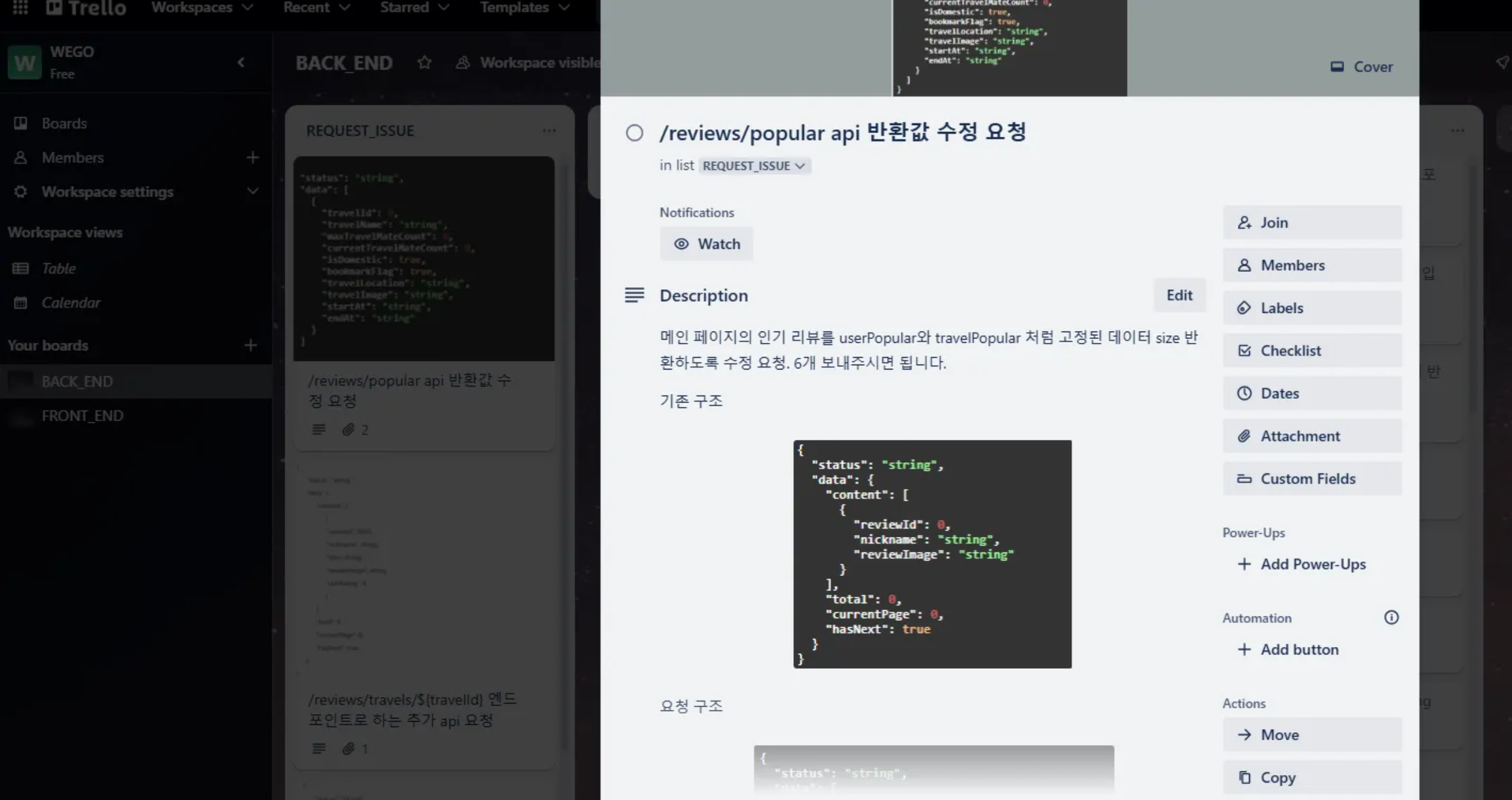
프론트 - 백 소통
프론트엔드와 백엔드 간의 소통은 Trello를 사용하여 이루어졌습니다. 각 카드들을 통해 현재 진행중인 개발 상황들에 대해 공유할 수 있도록 하였으며, 개발된 내용과 관련된 이슈들이나 추가 요구 사항들을 REQUEST 카드를 생성하여 전달하고 메시지를 주고 받았습니다.
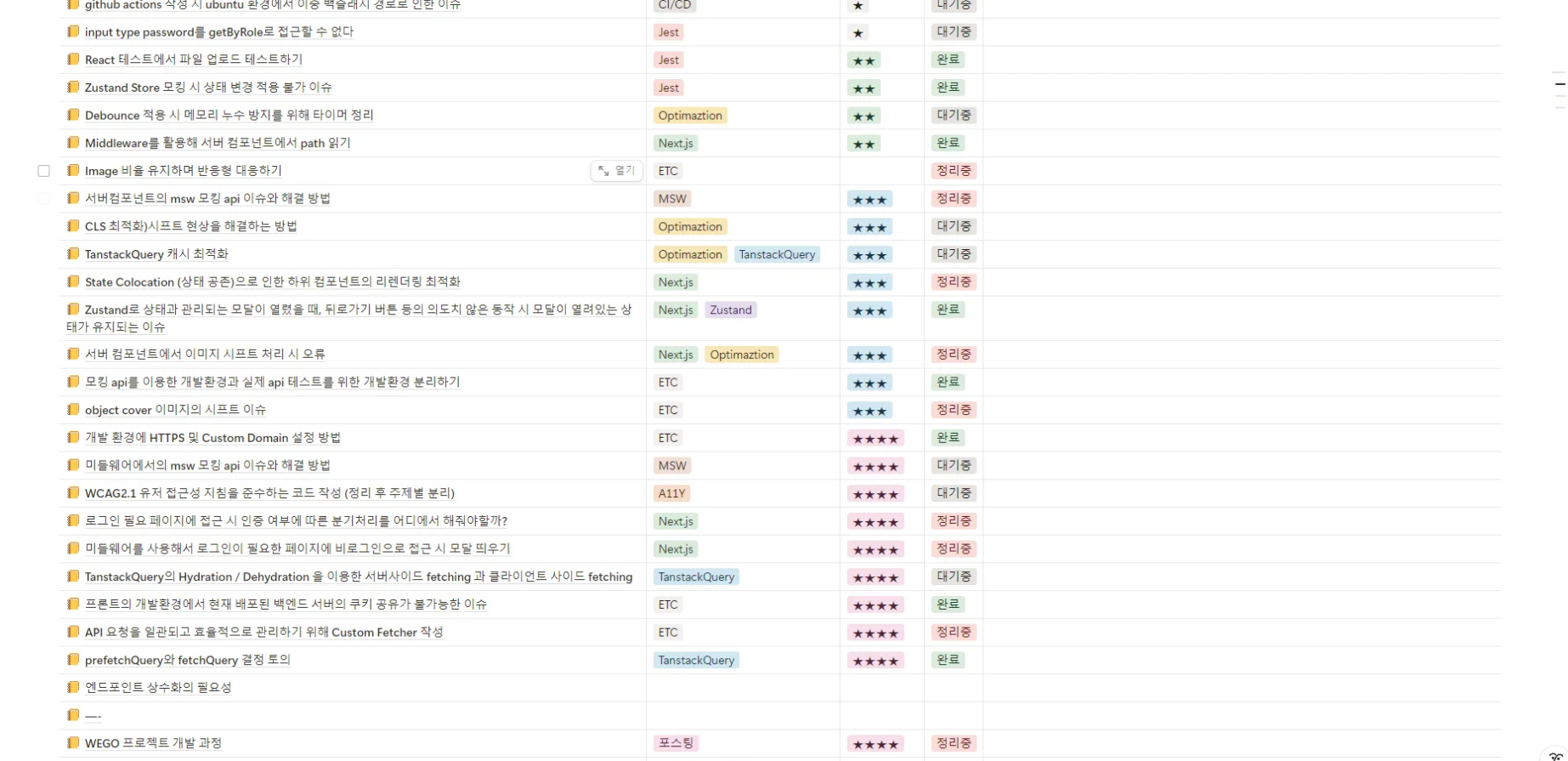
▫︎ 구현 사항 및 이슈 공유
개발 구현 사항 및 이슈등을 노션에 문서화하여 공유했습니다. 이를 통해 팀원과 구현 사항에 대한 의견을 주고 받을 수 있었으며, 자신이 맡은 업무 뿐만아니라 다른 팀원의 기능들까지 함께 고민하고 이해할 수 있는 계기가 되었습니다.
이슈 공유 시 정리된 문서를 통해 담당자가 직접 겪었던 경험들을 미리 확인하고 대안을 함께 고민할 수 있었으며, 각자의 구현 사항에 대해 복습할 수 있는 레퍼런스를 확보할 수 있었습니다.
▪︎ 프론트엔드 프로젝트 구조
1 | src/ |
관심사의 분리와 모듈화를 통해 코드의 재사용성과 유지보수성을 높이는데 중점을 두고 구조를 설정했습니다. 특히 도메인별로 관련 코드들을 그룹화하여 확장성과 가독성을 높였습니다.
- app/
- app 폴더의 경우 next.js 앱라우터를 이용할 때 정말 routable한 파일들만을 관리하는 것이 더 명시적인 구조라고 생각했습니다. 따라서 실제 라우팅되는 페이지들을 분리하여 관리했고, 하위에 구성되는 컴포넌트들은 components 폴더에서 관리했습니다.
- api/ - queries/
- 관심사를 분리하기 위해 api 폴더와 queries 폴더를 분리하였습니다. HTTP 요청의 기본 구조 정의, 엔드포인트 URL 관리, 요청/응답 타입 정의, HTTP method 정의와 같은 순수한 API 통신 로직은 api 폴더에서 관리하고 캐싱 전략, 에러처리 및 재시도 로직, 데이터 동기화 등 데이터 상태 로직에 대해서는 queries 폴더에서 Tanstack Query를 활용하여 관리했습니다.
- constants/
- 쿼리키, 인증관련 스키마와 같은 상수들을 따로 분리하여 관리함으로써 프로젝트의 확장성과 유지보수성을 향상시켰으며 팀 단위 개발에서 일관성있는 코드 작성이 가능했습니다.
- utils/
- 유틸리티 함수들 또한 분리하여 관리하여 컴포넌트 내에서의 함수 정의를 지양했습니다. 기능을 나타낼 수 있는 확실한 함수 네이밍을 통해 컴포넌트 내에서의 코드의 양을 줄이고 가독성을 향상시켰습니다.
▪︎ 마치며
이번 프로젝트에서는 MSW를 활용한 API 모킹과 체계적인 폴더 구조화를 통해 효율적인 개발 환경을 구축할 수 있었습니다. 특히 백엔드와의 의존성을 줄이고 병렬 개발을 가능하게 한 것이 가장 큰 성과였습니다.
또한 constants, queries, api 등의 폴더 구조화를 통해 코드의 역할과 책임을 명확히 분리함으로써, 유지보수성과 확장성을 크게 향상시켰습니다. 이러한 구조는 팀 단위의 개발에서 일관성 있는 코드 작성을 가능하게 했습니다.
앞으로도 지속적인 개선을 통해 더 나은 개발 경험을 만들어나갈 예정이며, 이러한 경험이 다른 프로젝트에도 좋은 참고가 되길 바랍니다.