패스트캠퍼스X야놀자 프론트엔드 개발 부트캠프_강사진 & 멘토 후기

지금까지 패스트캠퍼스 X 야놀자 부트캠프가 어떤식으로 진행되어 가는지를 소개했었는데요, 오늘은 부트캠프의 강사분들의 약력과 함께 실제 강의를 들어본 입장에서 후기를 전해드리고자 합니다. 또한 현재 진행되고 있는 멘토님과의 멘토링이 어떻게 도움이 되고있는지도 이야기 해볼게요.
부트캠프 강사진
박영웅 강사님

부트캠프에서 가장 먼저 강의를 통해 만나뵙게 된 박영웅 강사님! 프론트엔드의 기초라고 할 수 있는 HTML과 CSS, 그리고 Javascript에 대한 온라인 강의를 통해 만나뵈었습니다.
특히 Javascript의 경우에는 앞으로 배울 현업에서 쓰이는 중요한 기술들의 토대가 되기 때문에 확실히 공부해야한다고 생각했었습니다. 박영웅 강사님의 강의 같은 경우 우선적으로 이론에 대해 자세하게 정리하신 후 저희가 자주 접할 수 있는 사이트들을 실습으로 코딩하면서 이론들이 어떻게 실제 개발과정에서 쓰이는지를 학습할 수 있었습니다.
실습 강의로 API를 활용한 영화검색 사이트 만들기를 진행해 주셨는데요, 단순히 자바스크립트를 이용한 동적 구현뿐만 아니라 컴포넌트의 개념까지 설명해주시면서 실제 프로젝트의 적용할 수 있는 디렉토리 구성과 라우팅까지 학습할 수 있는 정말 좋은 강의라고 생각합니다.
사실 이 강의를 볼때마다 아쉬웠던 점이 하나 있어요. 저희가 두번째 과제로 Javascript를 활용한 사이트를 만들었었는데, 과제 시점이 이 실습 강의를 듣는 시점 이전이었기 때문에 많이 헤맸습니다. 과제를 제출한 뒤에 강의를 듣고는 ‘아 강의를 듣고 과제를 했다면 정말 수월하게 할 수 있었겠다.’라는 생각이 들었습니다.
안재원 강사님

안재원 강사님은 리액트와 여러가지 프레임 워크들을 강의해주셨습니다. 온라인 강의와 더불어 실시간 강의를 통해서 여러가지 실습들을 통해 다양한 개발 경험을 할 수 있도록 해주셨어요.
현업에서 현재 가장 많이 사용하고 있는(취업에 제일 중요하다고 해요) React와 프레임워크들을 강의해주셨어요. 특히 실습위주의 강의이다보니 매 강의마다 시간이 훌떡훌떡 갔습니다.
중요한 점은 실습을 통한 코드 따라치기를 벗어나 다시 한번 학습한 내용에 대해 되돌아보는 시간이 매우 중요하다는 생각을 하게 됬어요. 실습을 통해 개발을 매끄럽게 진행하시는데 따라치다보면 어느새 완성되어가는 결과물들이 내 실력이라는 착각을 할 수 있겠다고 생각했습니다.
막상 혼자 무에서부터 개발을 시작하려다보면 무엇을 해야할지 감이 안잡히고 헤매는 경우가 생기곤 해요. 그래서 그러지 않도록 어떻게 접근하셨고, 왜 이것부터 하셨지?, 왜 이 메소드를 사용하셨을까와 같은 점들을 바로바로 질문하면서 메모해두려고 노력을 많이 했습니다.
나동빈 강사님

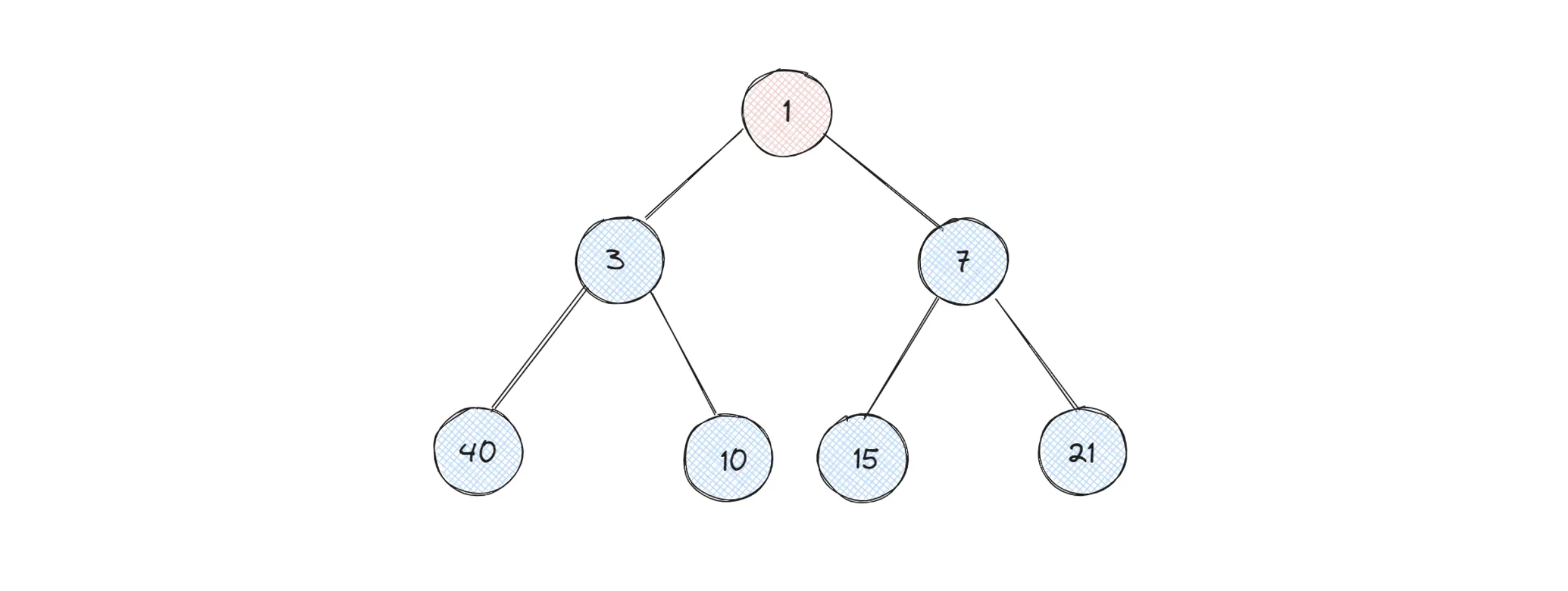
나동빈 강사님은 패스트캠퍼스 X 야놀자 부트캠프의 알고리즘 강의를 맡아주셨어요. 특히 저는 그룹스터디를 통해 매주 알고리즘 주제를 정하고 해당 알고리즘의 대표 문제들을 풀어오고 있었는데 도움을 많이 받았습니다.
이번 주의 주제가 BFS라면 해당 주제에 대한 나동빈 강사님의 녹화강의를 듣고 정리한 뒤에 문제를 풀면서 머리로 이해한 개념들을 문제 풀이에 적용하는 방식으로 공부했습니다.
특히 단순한 개념 강의만이 아니라 어떤 문제들을 만났을 때 해당 알고리즘을 떠올려야 하는지, 알고리즘이 문제마다 어떤식으로 구현되는지를 여러 예시 문제들을 풀어주시면서 자연스럽게 코딩테스트 문제들을 익힐 수 있도록 강의하시는게 정말 좋았습니다.
나동빈님은 사실 부트캠프를 시작하기 이전에도 유튜브를 통해 몇번 뵌적이 있었어요. 그때마다 어떤식으로 개발 공부를 할지, 코딩테스트 공부는 어떻게 준비해야하는지 등에 대해 많은 조언이 담긴 영상들을 통해 큰 도움을 받았다고 생각했는데 이번 부트캠프에서 강사진으로 만나뵙게 되니 너무 반가웠습니다.
그룹 7조 멘토님
서정현 멘토님
저희 그룹에서 멘토링을 해주시는 서정현 멘토님! 현재 현업에서 근무하고 계십니다. 따라서 개발 외적인 부분들에 대해서도 질문을 많이 드리고 도움이 되는 답변을 많이 얻어가는 것 같아요.
예를들어, 스타트업에 취직을 하게 된다면 어떤 기업들을 선택해야 하는지, 취업 프로세스 등과 같은 것들도 물어봅니다. (현업에서 근무하시면서 실제 팀원들을 뽑는 위치시다보니 취업관련 질문들에 대해서도 도움이 되는 답변들을 많이 해주세요!)
부트캠프가 진행되면서 개발와중 생기는 궁금점들을 모두 질문하기보다는 웹서칭을 통해 스스로 해결하게 되는 경우가 많아지면서 저희 조의 질문들이 점점 적어지는 것 같아요. 하지만 매 멘토링 시간마다 최대한 많은 도움을 주기 위해서 노력해주시는게 느껴집니다.
요즘에는 질문이 적어 시간이 남을 때는 면접관련 도움을 주시기로 해주셨어요. 실제 팀원들을 선별하는 경험과 취업을 위한 면접을 둘다 경험해보셨기 때문에 주시는 면접 질문들 하나하나 소중히 기록하고 답변할 수 있도록 준비하려고 노력하고 있습니다.
마치며
오늘 포스팅에서 패스트캠퍼스 X 야놀자 부트캠프의 강사분들과 멘토님을소개하고 부트캠프 과정 중 느꼈던 여러가지 점들을 적어보았습니다. 이 포스팅을 보시는 분들이면 아마 국비지원이나 부트캠프 등에 관심이 있으신 분들이라고 생각됩니다. 저는 패스트캠퍼스에서 운영하는 부트캠프가 좋은 강사분들과 커리큘럼을 가지고 있다고 생각해요. 제 포스팅들이 여러분의 선택에 도움이 되었으면 좋겠다고 생각합니다.