이벤트 핸들러는 이벤트가 발생했을 때 브라우저에 호출을 위임한 함수입니다. 이벤트가 발생하면 자바스크립트 엔진은 브라우저에게 이벤트 핸들러의 호출을 위임하게 하는 것을 이벤트 핸들러 등록이라고 합니다. 이벤트 핸들러를 등록하는 방법은 총 3가지입니다. ‘이벤트 핸들러 어트리뷰트 방식’, ‘이벤트 핸들러 프로퍼티 방식’, ‘addEventListener 방식’으로 이벤트 핸들러를 등록합니다.
이벤트 핸들러 어트리뷰트 방식은 오래된 코드에서 간혹 확인해볼 수 있기 때문에 이런 것이 있다고만 알아두는 것이 좋습니다. HTML과 자바스크립트는 마크업과 Interection이라는 서로 다른 관심사를 가지고 있기 때문에 혼재하는 것보다는 분리하는 것이 좋습니다. 이번 포스팅에서는 자바스크립트 내에서 핸들러를 등록하는 두가지 방식을 중점적으로 비교하겠습니다.
이벤트 핸들러 등록
이벤트 핸들러 어트리뷰트 방식
위에 서술한대로 예전 DOM level0 때나 관심사의 분리를 통한 웹 구성을 하기 이전의 레거시 코드로 남아있는 경우가 많습니다. 그러나 모던 자바스크립트에서는 이벤트 핸들러 어트리뷰트 방식을 사용하는 경우가 있기 때문에 알아둘 필요는 있습니다.
DOM 노드 객체는 이벤트에 대응하는 이벤트 핸들러 프로퍼티를 가지고 있으며, onclick과 같이 on 접두사와 이벤트의 종류를 나타내는 이벤트 타입으로 이루어져있습니다. 이벤트 핸들러를 등록하기 위해 이벤트를 발생시킬 대상 (이벤트 타깃)과 이벤트의 종류 (이벤트 타입) 그리고 이밴트 핸들러를 지정해주어야 합니다.
DOM Level 2에서 도입된 addEventListener 메서드 방식은 메서드를 사용하여 이벤트 핸들러를 등록할 수 있습니다. 첫번째 매개변수로 이벤트의 종류를 나타내는 이벤트 타입, 두번째 매개변수로 이벤트 핸들러를 전달합니다. 마지막 매개변수에는 이벤트를 캐치할 이벤트 전파단계를 지정합니다. 생략하거나 false를 지정하면 버블링 단계에서 이벤트를 캐치하고, true를 지정하면 캡처링 단계에서 이벤트를 캐치합니다.
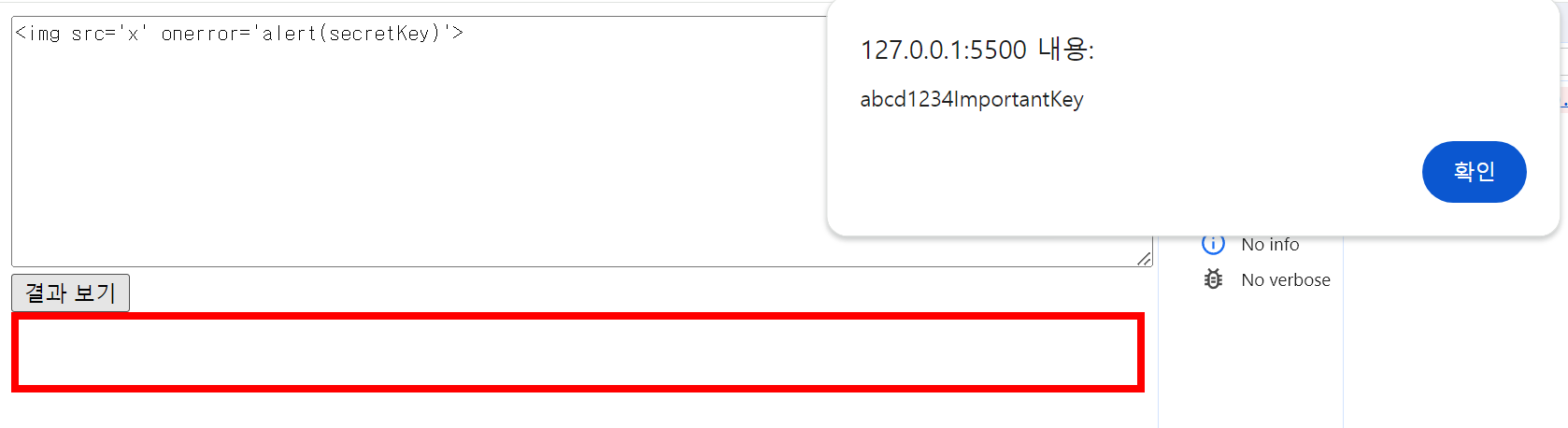
요소 노드의 innerHTML 프로퍼티에 할당한 HTML 마크업 문자열을 자바스크립트 엔진에 의해 파싱되어 DOM에 반영됩니다. 문제는 사용자로부터 입력받은 데이터를 innerHTML 프로퍼티에 할당하는 경우 엔진이 해당 라인을 파싱할 때 코드가 실행될 수 있는 위험이 있다는 것입니다. 만약 악의적 목적의 사용자가 input 값으로 악성 코드를 포함시킨다면 엔진이 파싱하는 과정에서 해당 코드가 평가되면서 실행되게 됩니다.
DOM 컬렉션 객체인 HTMLCollection 객체와 NodeList 객체는 DOM API가 여러 개의 값을 반환하기위한 객체입니다. 둘다 유사배열 객체이면서 이터러블이므로 for…of문을 포함한 여러 방법으로 순회가 가능합니다. 또한 스프레드 문법을 사용하여 배열로 간단히 변환할 수 있습니다.
HTMLCollection과 NodeList는 노드 객체의 상태를 실시간으로 반영하는 살아있는 객체라는 것입니다. HTMLCollection 객체는 언제나 ‘live 객체’로 동작하지만 NodeList 객체는 기본적으로 실시간으로 반영하지 않고 과거의 상태를 유지하지면 경우에 따라서는 live 객체로 동작합니다.
HTMLCollection 객체
HTMLCollection 객체는 getElementsByTagName, getElementByClassName 메서가 반환하는 노드 객체입니다. HTMLCollection 객체는 노드 객체의 상태 변화를 실시간으로 반영하는 살아있는 DOM 컬렉션 객체로 ‘live 객체’라고 부르기도 합니다.
위 코드에서 class 값이 ‘red’인 요소를 모두 취득하고 for문을 통해 모든 요소의 class 값을 ‘blue’로 변경하였습니다. 우리가 생각할 때 모든 li 요소의 class 값이 ‘blue’로 변경될 것이라고 생각하지만 예상대로 동작하지 않습니다.
이것은 HTMLCollection 객체가 live 객체의 특성을 가지고 있기 때문입니다. for문을 돌면서 i === 0 에서 첫번째 li의 class의 값을 ‘blue’로 변경합니다. 이 때 $elements가 참조하는 컬렉션 객체는 실시간으로 상태를 반영하여 HTMLCollection(2)[li.red, li.red] 상태가 됩니다. 따라서 i === 1 에서 적용되는 대상은 첫 선언한 요소들 중 세번째 li가 됩니다. 따라서 HTMLCollection 객체를 반복문을 통해 순회할 때에는 주의가 필요합니다.
NodeList 객체
HTMLCollection 객체의 부작용을 회피하기 위해 NodeList 객체를 이용하는 방법이 있습니다. querySellectorAll 메서드를 사용하면 DOM 컬렉션 객체인 NodeList를 반환합니다. 이 때 NodeList는 실시간으로 상태를 반영하지 않는 non-live 객체입니다. 그러나 childNodes 프로퍼티가 반환하는 NodeList객체는 live 객체로 동작합니다.
안전하게 DOM 컬렉션 객체를 활용하는 방법
HTMLCollection의 경우 live 객체의 특성 때문에 개발자가 예상치 못한 결과를 초래할 수 있다는 위험성이 있고, NodeList의 경우는 대부분 non-live 객체로 동작하지만 일부 상황에선 live-객체로 동작하는 위험성이 있습니다. 따라서 Dom 컬렉션 객체를 직접적으로 참조하는 것보다 배열로 변환하여 활용하는 방법을 추천합니다. ES6의 스프레드 문법을 통해 간단히 배열로 변환할 수 있습니다. 배열로 변환하게 되면 배열의 프로토타입을 상속받아 여러 메서드들도 사용할 수 있습니다.
HTMLCollection 객체는 forEach 메서드 사용이 불가능하고 NodeList 객체는 가능합니다. 보다 정확히 말하면 배열의 forEach 메서드는 배열만 사용이 가능하며 DOM 컬렉션 객체는 사용이 불가능합니다. 그 이유는 우리가 배열에서 사용하는 forEach 메서드가 Array.prototype의 프로퍼티를 상속받아 사용하고 있기 때문입니다. 따라서 비슷한 형태의 리스트 데이터지만 DOM 컬렉션 객체는 배열이 아니기 때문에 DOM을 조작하면서 기존의 배열의 문법들로 구현하는 것에는 한계가 있습니다.
NodeList는 forEach가 되는데요?
NodeList도 기존에는 forEach 메서드를 사용한 순회가 불가능 했습니다. 하지만 사용성을 위해 Web API에 추가된 기능입니다. 따라서 NodeList의 forEach 메서드는 배열의 forEach 메서드와 같은 동작을 하는 다른 메서드입니다.
지금까지 배웠던 것들을 전부 사용해서 많은 것을 해보고 싶었는데 막상 구현에 들어가니 막히는 것이 많았다. 막힐 때마다 구글링을 통해 확인하고 여러 시행착오를 거치게 되고, 계획했던 그날의 계획들이 모조리 깨지는 것을 보면서 단순 강의를 보고 배우는 것과 실제로 내가 고민하고 코드를 작성하는 것이 얼마나 차이가 큰지 새삼 느끼게 되었다.
Sass를 사용하면서 mixin을 실제로 써보니 어떤 코드까지를 중복으로 판단해야 할지 몰라서 고민하며 시간을 보내기도 했고, html의 접근성을 공부하고 적용하기 위해 코드를 짤 때 항상 생각하고 작성했지만 실제 자동 감사 도구에서는 안좋은 점수를 맞기도 했다.
또한 sprite-image의 활용이나 기획에 기반한 style 작성 등 초기에 계획했던 것들과 실제 내가 행한 5일은 많은 차이가 있었다. sprite-image는 이해가 부족하여 충분히 활용하지 못했고, Media Query 같은 경우에도 처음 기획한 코드 구성과 거리가 너무 멀었다. 시간에 쫓기고 시행착오를 반복하다 보니 마음이 급해졌고, 코드 또한 기획가 달리 점점 난잡해져갔다.
의외로 시간을 많이 소모하게 된 것이 디렉터리 구조나 한/영 font-face 구별과 같은 초기 세팅 관련한 부분이었는데, 처음엔 고생했지만, 다음 개발 시에는 훨씬 수월하게 할 수 있겠다는 자신감을 얻을 수 있었다.
결국 기획에서 중요한건 경험이고, 그것을 기반으로 좀더 현실적이고 완전하게 계획을 세워 코드 작성을 진행하는 것을 목표로 더욱 열심히 해나가야겠다.
멘토님의 코드리뷰
이번 개발에서 배웠던 기초에 더해 스스로 고민하고 찾아보면서 적용시킨 부분들이 있었다. 렌더링 성능에 대한 고민들이나 웹 접근성에서 스크린리더 사용자들을 최대한 고려한 코드를 작성한 것이 그것이다. 아직 초보자의 수박 겉핥기에 불과하겠지만, 멘토님은 그러한 고민을 한 것 자체에 대해 좋은 말씀을 해주셨다.
추가로 코드에서 개선할 점들을 짚어주셨다.
1) 유지보수성을 생각하여 모달창의 마크업 위치를 변경
페이지에 사용되는 공통 모달 배경은 추후 유지보수면에서 문서 상단에 위치시키면 추후 유지보수에 유리하다고 하셨다. 모달의 마크업을 쉽게 찾아갈 수 있을지에 대해 생각해본적이 없었는데 좋은 방향을 알게되었고, 바로 코드에 적용했다.
코드의 가독성이 나쁜 것도 짚어주셨는데 중복되는 코드들은 함수로 빼내어 관리하는 것을 권장하셨다. 기존 코드를 보면, 이벤트 리스너에서 코드가 반복되는 것을 볼 수 있는데, 이러한 경우 섹션이동 동작을 제어하는 함수로 분리하여 관리하고 함수가 어떻게 동작할지에 대한 값을 인수로 넘겨주게 만들었다. 실제로 반복되는 코드가 사라져 가독성이 높아졌고, 유지보수면에서 하나의 함수만을 수정하면 되기 때문에 훨씬 좋아보였다.
$prev.addEventListener('click', e => { moveSection(false); });
$next.addEventListener('click', e => { moveSection(false); });
3) 웹성능을 최적화할 수 있는 코드를 작성
ascript에서 변수에 DOM요소를 할당할 때 내 코드에서는 querySelector를 사용했다. 하지만 멘토님께서는 성능상으로는 getElementById가 좋다고 하시며 페이지가 많아질 수록 성능 차이가 심해질 것이라고 하셨다. 당장 지금의 프로젝트에서는 페이지의 수가 한정되어 있기 때문에 큰 차이가 없으므로 리팩토링할 필요는 없지만 추후 프로젝트에서 웹성능을 감안한다면 querySelector보다는 id를 지정하여 getElementById를 사용하는 쪽으로 코드를 작성해야겠다.
사실 DOM요소를 불러오는 방법에 대해 처음 듣는 이야기는 아니었다. getElementById가 더 성능이 좋다는 것도 알고있었다. 그러나 querySelector가 보다 성능은 낮지만 jquery보다는 성능이 좋다는 것을 알고있었고, jquery로도 복잡한 사이트들을 현업에서 구현하는데 querySelector로 복잡하지 않게 그냥 통일해서 사용하면 안될까? 라는 마음이 있었던 것 같다.
그러나 확실히 웹성능 면에서 개선된 방식으로 코드를 작성하는 습관을 들이는 것이 좋다는 말씀에는 동의한다. 다음 프로젝트 개발시에는 id를 읽어오는 쪽으로 작성하겠다.
Lighthouse
Lighthouse를 통해 구현한 사이트를 검사해본 결과 예상 외로 웹 접근성 측면에서 기대보다 낮은 점수를 받았다. 솔직히 좀 충격이었다. 이번 과제에서 접근성을 지키기 위해 WCAG2.1을 읽고 accessibility hidden style이나 WAI-ARIA 등의 활용으로 스크린리더 환경까지 고려했기 때문이다.
그러나 예상치 못한 부분에서 접근성을 지키지 못한 경우들이 있었다. 바로 버튼이나 링크등에 이미지를 직접적으로 삽입하고 텍스트를 입력하지 않았을 때의 문제였다.
Lighthouse를 통해 알게 된 웹 접근성의 취약점들을 개선하려 노력했다. 추가로 성능 면에서도 내가 개선이 가능한 부분들을 찾아내어 수정했다.
1) 웹 접근성 취약점 개선
텍스트가 없는 버튼을 디자인적 요소로 활용하여 링크를 연결한 것에 대한 지적이 있었다. 스크린리더 사용자의 입장에서 이러한 디자인적인 요소를 파악할 수 없는데, 파악할 수 없는 요소에 중요한 링크가 걸려있으니 문제가 있었다. WCAG2.1에서 의도적으로 스크린리더 사용자에게 정보를 전달하는 기능인 aria-label 속성을 확인하고 적용하였다.
1 2 3
// aria-label 적용 <a href="/"class="content-box-arrow" aria-label="해당 페이지로 이동"> <iclass="fa-solid fa-arrow-right"></i>
1 2 3 4 5 6
// aria-label 적용 <div class="carousel-btns"> <buttontype="button"class="carousel-btns-item active"data-num="1"aria-label="첫 번째 이미지로 이동"></button> <buttontype="button"class="carousel-btns-item"data-num="2"aria-label="두 번째 이미지로 이동"></button> <buttontype="button"class="carousel-btns-item"data-num="3"aria-label="세 번째 이미지로 이동"></button> </div>
2) 웹 성능 개선
사이트에서 애니메이션과 이미지들이 많이 사용되다 보니 성능적으로 많이 낮은 점수가 나오는 것 같았다. 우선적으로 코드 등의 수정 보다는 이미지 파일 자체의 크기들을 낮추는 것에 집중하였다.
이미지 최적화 프로그램을 통해 각 이미지들의 크기를 30% ~ 50% 낮춰주었고 유의미한 검사 결과의 차이를 얻었다. 추가로 Lazy Loding과 CDN을 활용한 이미지 최적화 방법들을 알게 되었는데 추후에 웹성능 개선을 위한 이미지 최적화 방식에 대해 제대로 알아보고 활용할 수 있게 하겠다고 다짐했다.
자바스크립트는 명령형, 함수형, 객체 지향 프로그래밍을 지원하는 ‘멀티 패러다임’ 프로그래밍 언어입니다. 다른 클래스 기반 객체 지향 프로그래밍과는 달리 프로토타입 기반의 객체 지향 프로그래밍을 구현합니다.
자바스크립트도 클래스가 있는데 왜 클래스 기반의 객체 지향 프로그래밍이라 칭하지 않는가?
ES6에 도입된 자바스크립트의 클래스는 함수이다. 따라서 생성자 함수와 동일하게 프로토타입 기반의 인스턴스를 생성한다. 기존 프로토타입 기반의 객체 지향을 구현하는 방식을 폐지하고 새로운 객체 지향 모델을 제공하는 것이 아니라 단지 기존 방식을 기존 클래스 문법 형태에 맞춘 ‘문법적 설탕’이라고 볼 수 있다.
객체 지향 프로그래밍이란?
객체 지향 프로그래밍은 전통적 명령형 프로그래밍 방식의 ‘절차지향적’ 관점에서 벗어나 객체의 집합으로 프로그램을 표현하려는 방식입니다. 객체 지향 프로그래밍은 실세계의 실체(사물이나 개념)을 인식하는 철학적 사고를 프로그래밍에 접목하려는 시도에서 시작합니다. 실체는 특징이나 속성을 가지고 있고 이를 통해 실제를 인식하거나 구별할 수 있습니다.
예를 들어, 사람은 이름, 나이, 키, 체중, 직업, 학력 등 다양한 속성을 갖습니다. 우리는 속성을 통해 특정한 사람을 다른 사람과 구별하여 인식할 수 있습니다. 이러한 방식을 프로그래밍에 적용해보겠습니다. 만약 어떠한 사람의 이름과 나이, 직업에만 관심이 있다면 해당 속성만을 간추려내어 표현할 수 있습니다. 이것을 추상화 라고 합니다.
1 2 3 4 5
const person = { name: "namgung jong min", age: 29, job: baeksu, };
개발자는 이름과 나이, 직업 속성으로 위 객체를 다른 객체와 구별하여 인식할 수 있습니다. 이처럼 속성을 통해 여러 값을 하나의 단위로 구성한 복합적 자료구조를 객체라고 합니다. 즉 객체 지향 프로그래밍은 독립적인 각 객체들의 그룹을 활용해 프로그래밍을 하는 방식입니다.
원이라는 개념을 객체로 만들어보았습니다. 원에는 반지름이라는 속성이 있습니다. 이 속성을 활용하여 지름과 둘레를 구할 수 있습니다. 이 때 반지름은 원의 상태를 나타내는 데이터이며, 원의 지름과 둘레를 구하는 것은 동작입니다.
이처럼 객체 지향 프로그래밍은 객체의 상태를 나타내는 데이터와 동작을 나타내는 데이터를 묶어서 생각합니다. 따라서 객체는 상태 데이터와 동작을 하나의 논리적인 단위로 묶은 복합적인 자료구조라고 할 수 있습니다.
프로토타입을 이용해 상속을 구현
상속은 객체 지향 프로그래밍의 핵심 개념으로, 어떤 객체의 프로퍼티 또는 메서드를 다른 객체가 상속받아 그대로 사용할 수 있는 것을 말합니다. 자바스크립트는 프로토타입을 기반으로 상속을 구현하여 불필요한 중복을 제거합니다. 중복을 제거하는 것은 개발 비용을 줄일 수 있는 방법이기 때문에 중요합니다.
위에서 Circle 생성자 함수는 인스턴스를 생성할 때마다 동일한 동작을 하는 getArea 메서드를 중복 생성하며 모든 인스턴스가 중복 소유합니다. getArea 메서드는 Circle 생성자 함수만이 소유하며 생성된 인스턴스들은 해당 메서드를 공유하여 사용하는 것이 바람직합니다.
생성자 함수에 의해 생성된 모든 인스턴스가 동일한 메서드를 중복 소유하는 것은 메모리를 불필요하게 낭비합니다. 이번엔 상속을 통해 불필요한 중복을 제거해 보겠습니다.
위 코드에서 생성한 인스턴스가 getArea 메서드를 공유해서 사용할 수 있도록 프로토타입에 추가했습니다. 모든 인스턴스들은 자신의 프로토타입, 즉 상위 객체 역할을 하는 Circle.prototype의 모든 프로퍼티와 메서드를 상속받습니다. 즉 자신의 상태를 나타내는 radius 프로퍼티만 개별적으로 소유하고 내용이 동일한 메서드는 상속을 통해 공유하여 사용하는 것입니다.
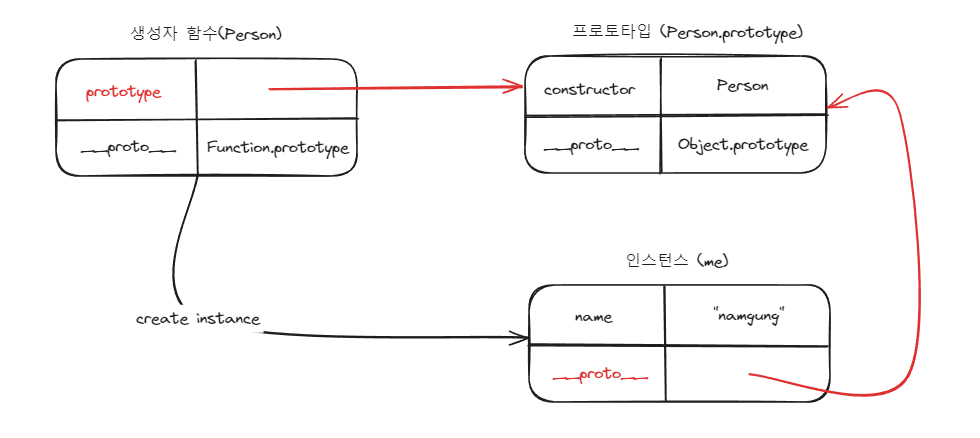
생성자 함수 / 프로토타입 / 인스턴스의 관계
프로토타입의 내부 동작을 이해하기 위해서 도표를 통해 생성자 함수와 프로토타입, 그리고 인스턴스의 관계를 살펴보겠습니다. 그 전에 내용의 이해를 위해 용어를 정리하고 가는 것이 필요합니다.
프로토타입 객체 (프로토타입)
프로토타입 객체는 상속을 구현하기 위해 사용됩니다. 프로토타입은 어떤 객체의 상위 객체의 역할을 하는 객체로서 다른 객체의 공유 프로퍼티를 제공합니다. 상위 객체의 프로퍼티를 공유받은 하위 객체는 상위 객체의 프로퍼티를 자유롭게 사용할 수 있습니다.
프로토타입 내부 슬롯 ([[Prototype]])
모든 객체는 [[Prototype]]이라는 내부 슬롯을 가지며, 이 내부 슬롯의 값은 프로토타입의 참조입니다. 어떤 프로토타입이 저장될지는 객체 생성 방식에 의해 결정됩니다. 즉 객체 생성 방식에 따라 프로토타입이 결정되고 [[Prototype]]에 저장됩니다.
__proto__ 접근자 프로퍼티
모든 객체는 __proto__ 접근자 프로퍼티를 통해 자신의 프로토타입, 즉 [[Prototype]] 내부 슬롯에 간접적으로 접근할 수 있습니다. 이 때 __proto__ 접근자 프로퍼티는 객체가 직접 소유하는 프로퍼티가 아닙니다. __proto__접근자 프로퍼티는 프로토타입이 소유하며 인스턴스는 해당 프로퍼티를 상속을 통해 사용합니다.
프로토타입에 접근하기 위한 __proto__를 인스턴스가 아닌 프로토타입이 소유하는 이유는 단방향의 체인을 구성하기 위함입니다. 프로토타입 체인 상의 각 객체들은 __proto__ 접근자 프로퍼티를 상위 객체에서 상속받아 사용하며 이를 통해 프로토타입 체인을 구축합니다.
중요한 것은 객체의 프로퍼티 자체에 접근하는 것이 아니라 반드시 __proto__를 통해서만 객체에 접근하여 프로퍼티를 검색한다는 점입니다. 프로토타입 객체에 개발자가 직접 관여하는 것은 상호 참조의 비정상적인 체인 형성에 대한 위험이 있습니다. 이는 프로토타입이 순환 참조의 체인을 형성하여 무한루프에 빠질 수 있기 때문에 프로토타입 체인은 반드시 단방향 링크드 리스트로 구현되어야 합니다.
따라서 자바스크립트는 체크없이 객체에 직접 접근하여 프로토타입을 교체할 수 없도록 __proto__ 접근자 프로퍼티를 통해서만 프로토타입 객체에 접근할 수 있도록 구현되어 있습니다.
프로토타입 프로퍼티
프로토타입 프로퍼티는 함수 객체만이 소유하는 프로퍼티로 생성자 함수가 생성할 인스턴스의 프로토타입을 가리킵니다. 따라서 prototype 프로퍼티는 생성자 함수로서 호출할 수 없는 함수, 즉 non-constructor인 화살표 함수와 ES6 메서드 축약 표현으로 정의한 메서드에서 존재하지 않습니다.
생성자 함수로 인스턴스 생성 시 프로토타입
생성자 함수를 new 키워드를 통해 호출하면 [[Construct]] 내부 메서드가 호출되며 인스턴스가 생성됩니다. 이 때 생성자 함수가 생성될 때 함께 생성된 프로토타입과 인스턴스가 연결됩니다.
생성자 함수가 생성한 인스턴스는 생성자 함수의 프로토타입 프로퍼티에 저장된 프로토타입을 상속받습니다. 인스턴스 입장에서 __proto__ 접근자 프로퍼티를 통해 프로토타입에 접근할 수 있습니다.
모든 프로토타입은 constructor 프로퍼티를 갖습니다. 이 constructor 프로퍼티는 prototype 프로퍼티로 자신을 참조하고 있는 생성자 함수를 가리킵니다.
리터럴로 생성한 객체의 생성자함수와 프로토타입
위에서 살펴본 것과 같이 생성자 함수로 생성된 인스턴스는 프로토타입의 constructor 프로퍼티에 의해 생성자 함수와 연결됩니다. 이 때 constructor 프로퍼티가 가리키는 생성자 함수는 인스턴스를 생성한 함수입니다.
그렇다면 리터럴 표기법에 의해 생성된 객체의 constructor 프로퍼티가 가리키는 대상은 무엇일까요? 리터럴 표기법에 의해 생성된 객체의 경우 프로토타입의 constructor 프로퍼티가 가리키는 생성자 함수가 반드시 객체를 생성한 생성자 함수는 아닙니다.
위 코드에서 obj2는 Object 생성자 함수로 생성된 것이 아닙니다. 그러나 constructor 프로퍼티는 Object를 가리킵니다. 그렇다면 사실 객체 리터럴로 생선한 객체도 내부적으로는 Object 생성자 함수를 사용하여 생성되는 것은 아닐까요?
ECMA Script 사양서에는 객체 리터럴이 평가될 때 추상 연산을 호출하여 빈 객체를 생성하고 프로퍼티를 추가하도록 정의되어있습니다. 그러나 Object 생성자 함수의 경우 undefined나 null을 인수로 전달하면서 호출할 때에만 추상 연산을 호출하여 객체를 생성합니다.
따라서 객체 리터럴에 의해 생성된 객체는 Object 생성자 함수가 생성한 객체가 아닙니다.
함수또한 마찬가지인데 함수 선언식으로 생성된 함수 객체는 Function 생성자 함수가 아니지만 객체의 프로토타입의 constructor 프로퍼티는 Function을 가리킵니다.
생성자 함수가 아닌 리터럴 표기법에 의해 생성된 객체도 상속을 위해서는 프로토타입이 반드시 필요합니다. 따라서 자바스크립트는 리터럴 표기법으로 생성된 객체에도 가상적인 생성자 함수를 부여합니다. 프로토타입은 생성자 함수와 더불어 생성되며 prototype, constructor 프로퍼티에 의해 연결되어있기 때문입니다.
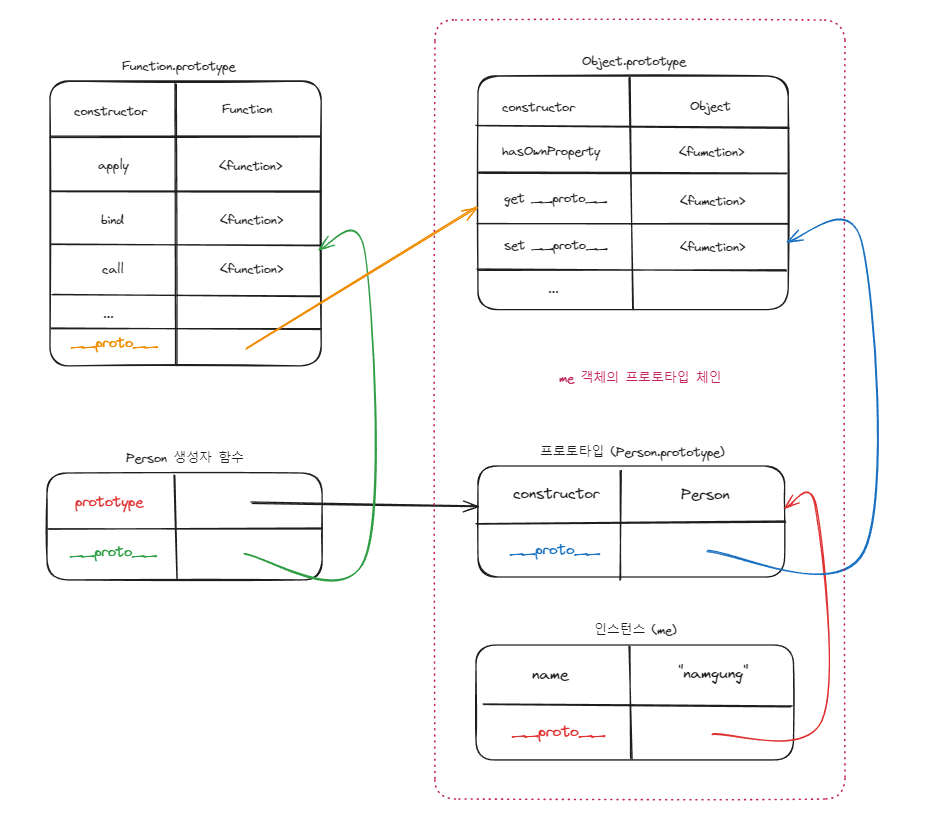
프로토타입 체인
자바스크립트는 객체의 프로퍼티에 접근하려고 할 때 해당 객체에 접근하려는 프로퍼티가 없다면 [[Prototype]] 내부 슬롯의 참조를 따라 자신의 부모 역할을 하는 프로토타입의 프로퍼티를 순차적으로 검색합니다. 이를 프로토타입 체인이라고 합니다.
자바스크립트 엔진은 프로토타입 체인을 따라 프로퍼티와 메서드를 검색합니다. 즉 자바스크립트 엔진은 객체 간의 상속 관계로 이루어진 프로토타입의 계층적인 구조에서 객체의 프로퍼티를 검색하며 프로토타입 체인을 한마디로 말하자면 상속과 검색을 위한 매커니즘이라고 할 수 있습니다.
전역 변수의 사용은 위험합니다. 따라서 반드시 전역 변수를 사용해야 할 이유가 있는 것이 아니라면 지역 변수를 사용해야 합니다. 이번 주제에서 전역 변수의 사용이 왜 위험하며, 그러면 어떠한 방식으로 전역 변수의 사용을 최소화할 수 있는지 알아보겠습니다.
변수의 생명 주기
변수는 선언에 의해 생성되고 할당을 통해 값을 갖게 됩니다. 그리고 언젠가 소멸합니다. 즉 생물과 유사한, 생성되고 소멸되는 생명 주기가 있습니다. 전역 변수의 문제점을 알아보기에 앞서 내용의 이해와 공감을 위해 지역 변수와의 생명 주기를 비교해보겠습니다.
지역 변수의 생명 주기
1 2 3 4 5 6 7 8 9 10
functionfoo(){ ---------------------------------- ① var x = 'local'; ----------------- ② console.log(x); //output: 'local' return x; ---------------------------------- ③ }
foo(); console.log(x); // Reference Error
지역 변수 x는 함수가 호출되기 이전까지는 생성되지 않습니다. foo 함수를 호출하지 않으면 함수 내부의 변수 선언문이 실행되지 않기 때문입니다. 변수 x의 선언은 함수가 호출되어 함수 몸체의 코드가 한 줄씩 실행되기 직전에 자바스크립트 엔진에 의해 실행됩니다.
위 코드의 경우 ①에서 x 변수가 선언되고 undefined로 초기화됩니다. 이후 함수 몸체를 구성하는 문들이 순차적으로 실행되면서 ②에서 변수에 값이 할당 됩니다. 그리고 함수 몸체의 모든 코드를 실행하고 (③) 함수가 종료되면 x 변수도 소멸되어 생명 주기가 종료됩니다.
따라서 함수 내부에서 선언된 지역 변수 x는 함수가 호출되어 실행되는 동안에만 유효하고 이는 지역 변수의 생명 주기가 함수의 생명 주기와 일치한다는 것을 말해줍니다.
또한 지역 변수의 선언은 스코프 단위로 동작하게 됩니다. 이는 각 함수가 실행되는 시점의 지역 변수의 식별자 이름이 같다 하더라도 서로를 간섭하지 않는다는 것을 의미합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
var x = "global";
functionfoo() { var x = "local"; console.log(x); //output: 'local' return x; }
functionbar() { var x = "local2"; console.log(x); //output: 'local2' return x; }
foo(); bar(); console.log(x); // Reference Error
전역 변수의 생명 주기
함수와 달리 전역 코드는 명시적인 호출 없이 실행됩니다. 즉 전역 코드는 어떠한 진입점이 없고 코드가 로드되자마자 곧바로 해석되고 실행됩니다. 함수가 함수 몸체의 모든 문이 실행되거나 반환문이 실행 되면 종료되는 것에 반해 전역 코드는 자바스크립트의 모든 코드가 실행되어 더 이상 실행할 문이 없을 때 종료됩니다.
var 키워드로 선언한 전역 변수는 전역 객체의 프로퍼티가 됩니다. 이는 전역 변수의 생명 주기가 전역 객체의 생명 주기와 일치한다는 것을 말합니다. 또한 let과 const 키워드로 선언한 전역 변수가 저장된 렉시컬 환경이 전역 객체와 연결되어 있기 때문에 마찬가지로 전역 객체와 생명 주기가 같습니다.
브라우저 환경에서 전역 객체는 window이므로 전역 변수는 웹페이지를 닫을 때까지 유효합니다.
전역 변수의 문제점
암묵적 결합
전역 변수를 선언한 의도는 ‘코드 어디서든 참조하고 할당할 수 있는 변수를 사용하겠다.’ 라는 것입니다. 이는 모든 코드가 전역 변수를 참조하고 변경할 수 있는 암묵적 결합 을 허용하는 것입니다. 변수의 유효 범위가 크면 클 수록 코드의 가독성은 나빠지고 의도치 않은 변수의 접근이나 변경이 일어날 위험성도 증가합니다.
메모리 리소스의 증가
전역 변수는 생명주기가 깁니다. 웹페이지가 종료될 때까지 전역 변수의 정보를 메모리에 저장해두어야 합니다.
느린 참조 속도
자바스크립트는 식별자를 검색할 때 현재 실행중인 실행 컨텍스트 스택의 렉시컬 환경에서 상위 컨텍스트의 렉시컬 환경으로 스코프 체인을 따라 검색을 실행합니다. 따라서 전역 변수는 스코프 체인 상의 종점에 존재하기 때문에 변수를 참조하기 위한 검색 속도가 가장 느립니다.
네임스페이스 오염
자바스크립트는 파일이 분리되어 있다 하더라도 전역 스코프를 공유합니다. 따라서 스크립트 파일들의 규모가 커지면 커질 수록 다른 파일들 내에서 동일한 이름으로 명명된 전역 변수나 전역 함수가 같은 스코프 내에 존재할 위험이 있으며, 이로 인한 의도치 않은 결과를 가져올 수 있습니다.
Injection 공격에 취약
앞서 전역 변수의 생명 주기의 설명에서 전역 변수는 웹페이지를 닫을 때까지 유효하다고 했습니다. 이것은 웹페이지 내에서 여러 변수에 접근이 가능하다는 위험성을 내포합니다. 즉 XXS와 같은 Injection 공격에 취약합니다.
위 예시는 XXS 공격을 통해 자바스크립트 변수에 액세스하는 상황을 구현해본 것입니다. 이처럼 전역 변수는 웹페이지가 닫힐 때까지 유효하기 때문에 중요한 정보를 저장해둔다면 여러 스크립트 공격에 의해 정보가 탈취될 수 있습니다.
전역 변수의 사용을 억제하는 방법
앞서 말한 내용들을 통해 전역 변수의 사용을 지양해야 된다는 것을 확인해보았습니다. 전역 변수를 반드시 사용해야 할 이유가 없다면 지역 변수를 사용해야 합니다. 변수의 스코프는 좁을 수록 좋습니다. 전역 변수의 사용을 억제하고 생명 주기를 짧게 가져가는 몇 가지 방법에 대해 알아보겠습니다.
즉시 실행 함수
즉시 실행 함수는 함수 정의와 동시에 런타임 내 단 한번만 호출되는 함수입니다. 모든 코드를 즉시 실행 함수로 감싸면 모든 변수는 즉시 실행 함수의 지역 변수가 됩니다.
1 2 3 4
(function () { const foo = 10; // ... 생략 })();
이 방법을 사용하면 추가적인 스크립트의 스코프를 전역 스코프에서 분리할 수 있습니다. 따라서 여러 스크립트 간 식별자의 충돌을 피하기 위해 라이브러리 등에서 자주 사용됩니다.
모듈 패턴
모듈 패턴은 클래스를 모방해서 관련이 있는 변수와 함수를 모아 즉시 실행 함수로 감싸 하나의 모듈을 만듭니다. 모듈 패턴은 클로저를 기반으로 동작합니다.
모듈 패턴을 사용하면 전역 변수의 사용을 억제할뿐만 아니라 캡슐화까지 구현할 수 있습니다. 캡슐화를 통해 코드 내에서 변수에 접근하는 것 자체를 차단할 수 있습니다.
위 코드는 dirty의 값이 ‘참’일 때만 error 여부를 판별하여 error가 ‘참’일 경우 ‘Error’ 문자열을 렌더링하는 코드입니다. dirty의 값이 ‘거짓’일 경우 error 여부와 관계없이 ‘Error’ 문자열을 렌더링합니다.
*null 병합 연산자 (A ?? B)
논리합 연산자를 사용할 때 주의할 점은 연산자가 각 피연산자의 Truthy / Falsy 값을 판단한다는 점입니다. 위 논리합 연산자의 예시에서 dirty값이 string 데이터 타입이라고 가정해봅시다.
개발자가 빈 문자열 또한 dirty 값이 있다고 가정 한다해도 빈 문자열 ‘’은 Falsy 값으로 판단되어 자바스크립트는 B를 평가하게 됩니다. 이것은 개발자의 의도대로 동작한 것이 아닙니다.
Truty / Falsy 값을 판별하는게 아니라 값 자체가 할당되지 않았거나(undefined) 명시적으로 빈 값이라고 표현된 요소(null)를 판단하고 싶다면 null 병합 연산자 를 사용할 수 있습니다. null 병합 연산자를 사용하면 피연산자가 null 또는 undefined인지 여부만을 판단하게 됩니다.
위 코드의 경우 만약 http 요청으로 받아온 data의 값이 없을 경우 에러를 출력하여 페이지 렌더링이 불가능합니다. 만약 data가 있을 경우 해당 요소를 렌더링하고, 없다면 저 부분만을 제외한 상태로 정상적인 렌더링을 하기 위해 옵셔널 체이닝 연산자를 활용할 수 있습니다.
단순히 제목의 내용만 적는 것이 아니라 앞에 Feat: 이라는 단어가 붙어있는데요, 이는 해당 커밋의 타입을 명시하는 부분입니다.
Feat : 새로운 기능 추가
Fix : 버그 수정
Env : 개발 환경 관련 설정
Style : 코드 스타일 수정 (세미 콜론, 인덴트 등의 스타일적인 부분만)
Refactor : 코드 리팩토링 (더 효율적인 코드로 변경 등)
Design : CSS 등 디자인 추가/수정
Comment : 주석 추가/수정
Docs : 내부 문서 추가/수정
Test : 테스트 추가/수정
Chore : 빌드 관련 코드 수정
Rename : 파일 및 폴더명 수정
Remove : 파일 삭제
issue, pull request template
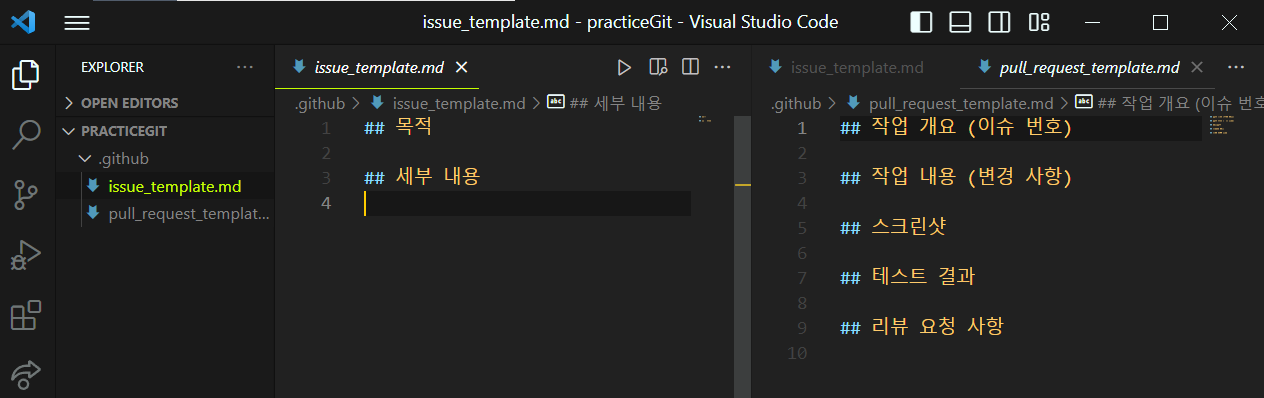
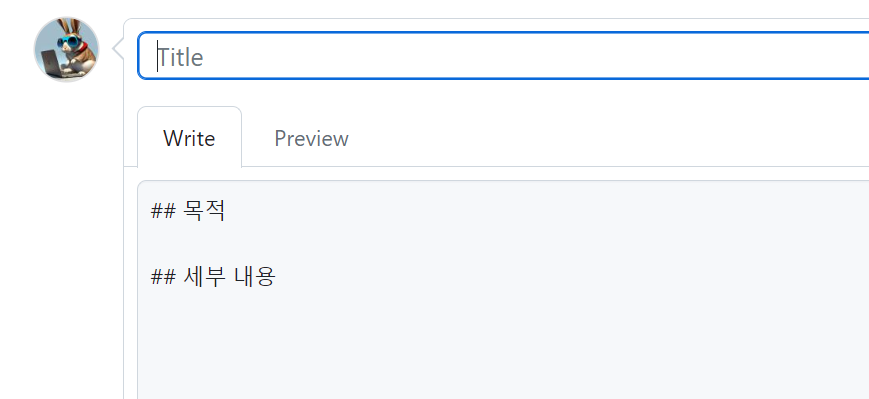
template은 issue나 request를 작성하기 위한 틀을 말합니다. 우리가 issue나 pull request를 작성할 때 일일이 목차를 직접 작성하게 되면 시간이 오래 걸리게 됩니다. 또한 issue 나 pull request를 작성하는 팀원들 간의 양식을 지킬 수 있게 됩니다.
vscode에서 template 설정해보기
git으로 관리되는 폴더 내부에 .github 폴더를 만든다.
main 브랜치로 push한 이후에 github내에서 이슈 생성으로 들어가보면 템플릿이 적용된 것을 확인할 수 있습니다.
issue의 경우, 단순 작업 정리 용도가 아닌, 다양한 목적으로 생산될 수 있습니다.
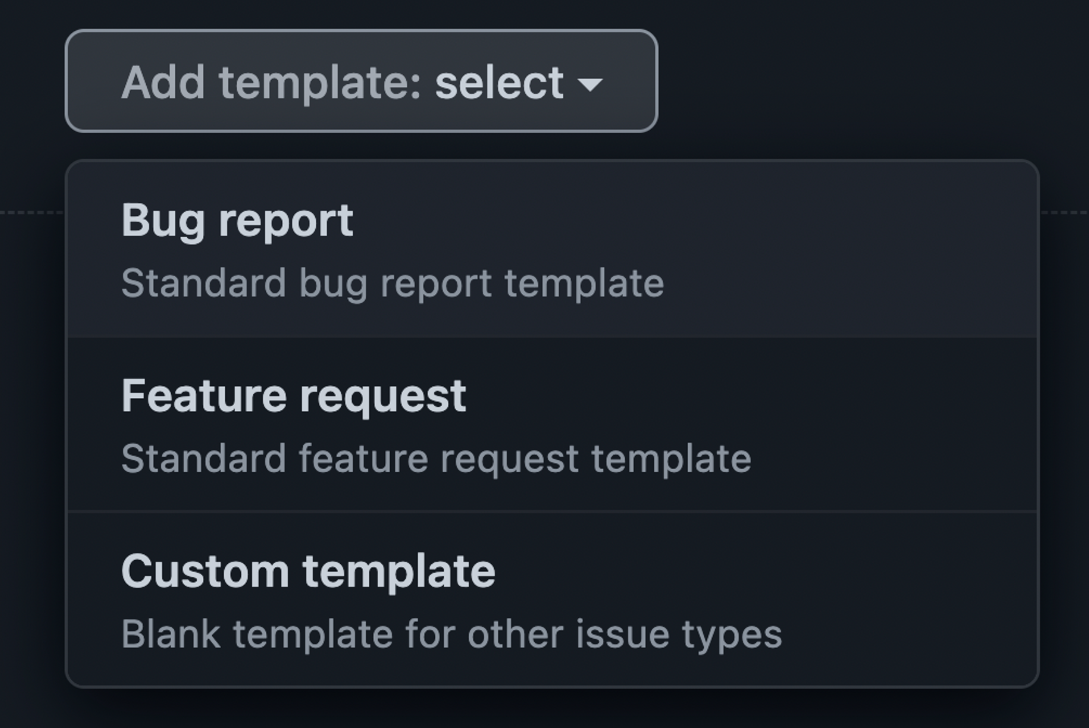
때문에 여러 개의 issue template를 만들 수 있는 github 자체 기능이 있습니다.
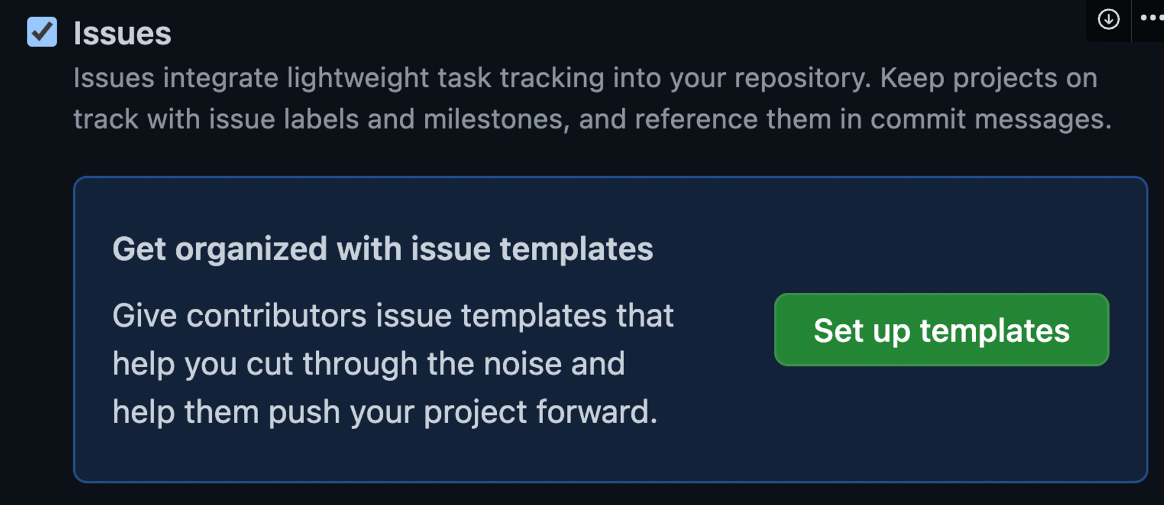
깃허브 레포지토리 설정에 들어가 General 메뉴에서 스크롤을 내리다보면 아래와 같이 setup templates 버튼이 보입니다.
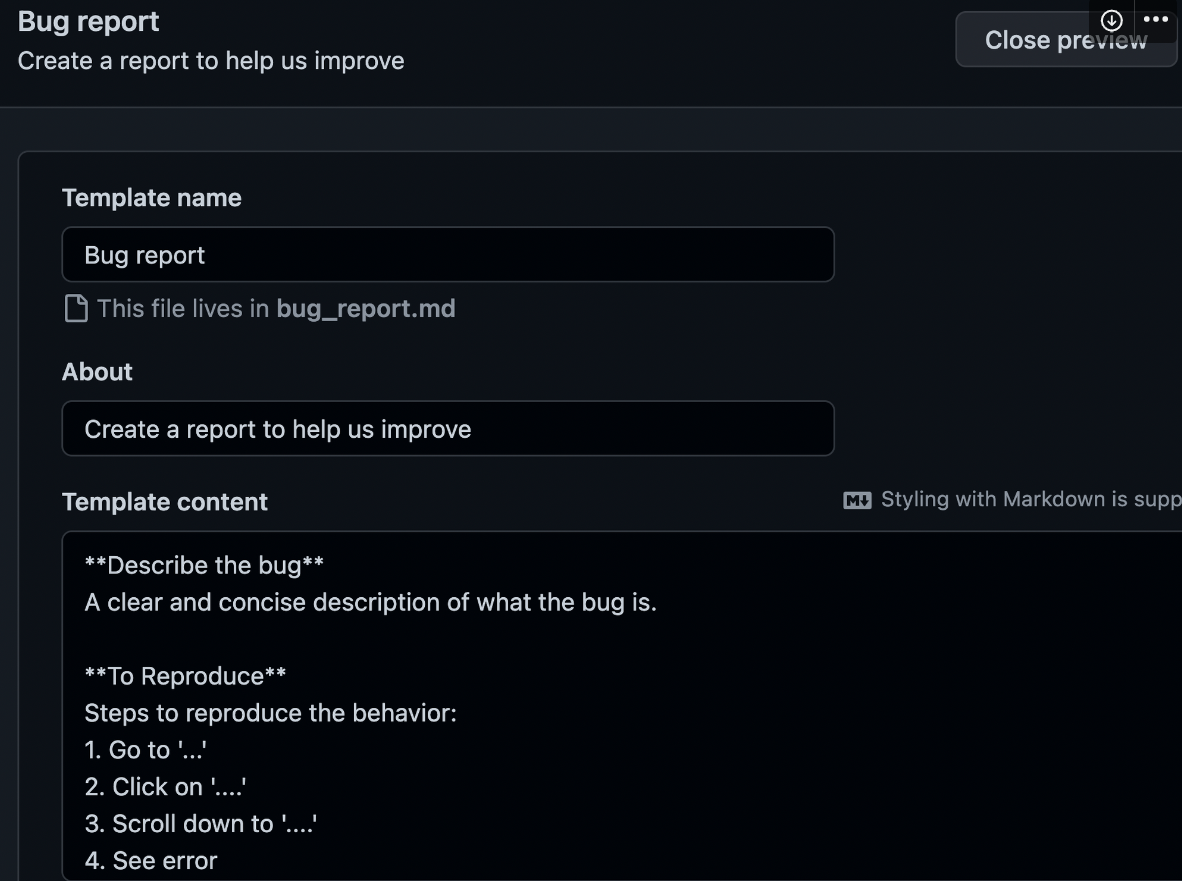
기본적으로 깃허브에서 기본적으로 마크다운을 어느정도 작성해 놓은 템플릿을 추가할 수 있는데, preview and edit 버튼을 눌러서 수정도 가능합니다.
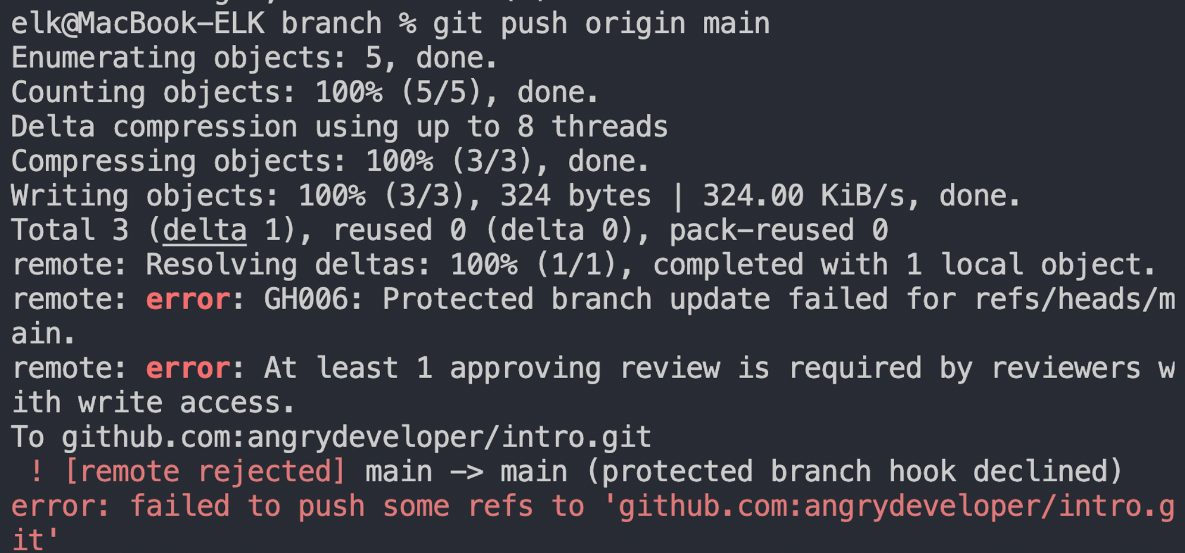
Branch Protection
지금까지 예시에서는 main 브랜치에 바로 push를 했는데요, main 브랜치에 바로 push하는 행위는 위험합니다.
그게 바로 pull request를 사용해야 하는 이유인데요 주니어 개발자가 에러가 나는 코드를 잘못해서 바로 main 브랜치에 push를 하게 된다면 서비스 사용자는 갑자기 에러를 마주하게 될 것입니다.
때문에 실수를 방지하기 위해서 main 브랜치에 push하는 것을 원천적으로 차단해버려야 합니다.
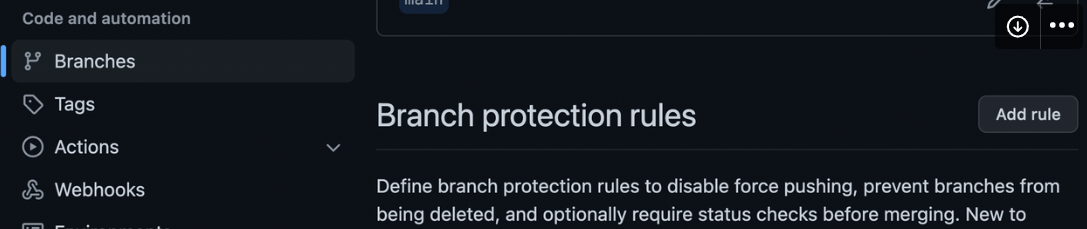
우리는 github에서 branch protection이라는 방식으로 이를 해결할 수 있습니다.
레포지토리 설정에 들어가서 왼쪽에서 브랜치를 선택하면 add rule 버튼을 확인할 수 있습니다.
여기에 보호하고자 하는 브랜치 이름을 적어주면 됩니다. 또한 여기서 pattern도 지정이 가능합니다.(feature*라고 작성하면 feature라는 접두어를 가진 모든 브랜치에 protection이 적용됩니다.)
이제 main 브랜치가 보호되었습니다. main 브랜치에 직접 push를 해보면, 보호된 브랜치라서 push가 불가능하다고 에러가 나오게 됩니다.
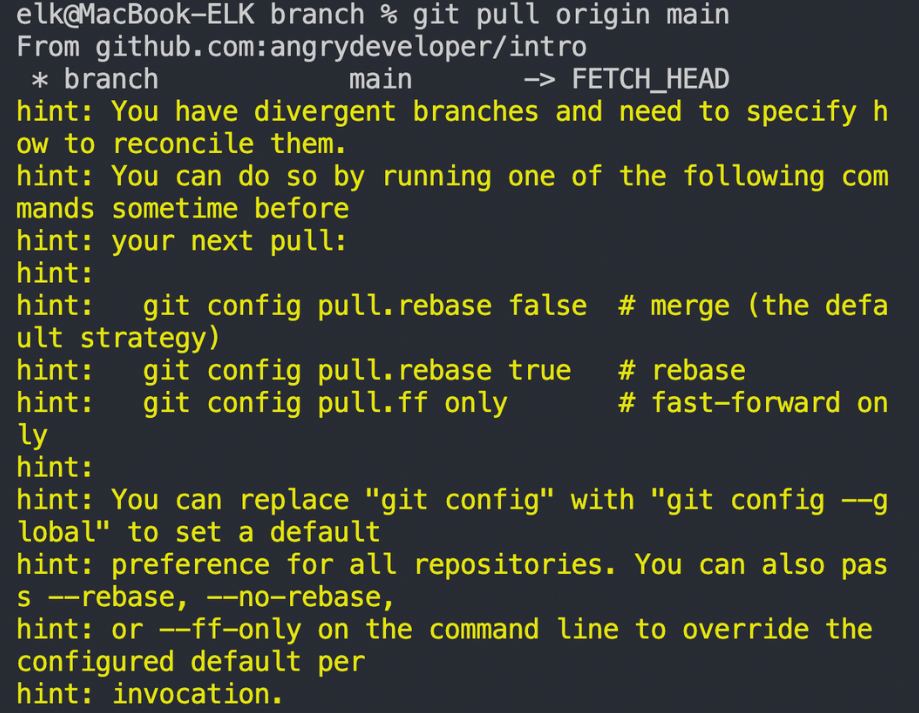
git사용 꿀팁 / pull 오류를 만났을 때
위 에러는 현재 가진 로컬 브랜치의 커밋 이력과, 리모트 브랜치의 커밋 이력이 충돌하는 경우입니다. 여러번의 push 요청이 오게되면 git 입장에서는 이력을 어떻게 합치는 것이 좋은지 선택하지 못하게됩니다.
git pull의 근본적인 원리는 github쪽의 리모트 브랜치와 로컬 브랜치를 merge, rebase를 통해 합치는 것으로 이루어집니다. 그런데 해당 에러는 git이 pull을 할 때 정확히 merge, rebase 혹은 fast-forward merge 중에 무엇을 선택할지 모르겠으니 사용자에게 지정해달라고 하는 것입니다.
main 브랜치에 대해서 직접 push하지 않고 pull request를 통해서만 merge를 하게 되면 이 에러가 발생하지 않을 것입니다.
보통 개발 블로그에서 git config pull.rebase false 같은 명령어를 입력하라고 할텐데, 이렇게 git 절정 자체를 바꾸기 보단,
1
git pull origin main --no-ff
와 같이 내가 원하는 pull 형태가 어떤 것인지 지정해주는 것이 좋습니다. 이후에 conflict가 발생한 부분을 수정한 뒤에 commit까지 해주면 해결이 됩니다.
git으로 관리하지 않을 대상 설정
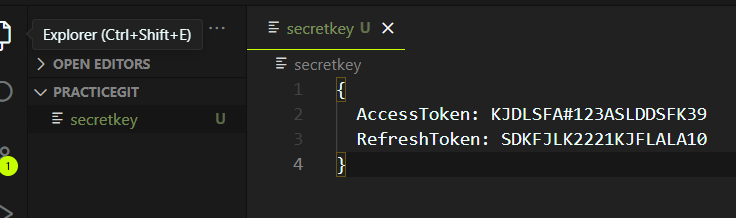
개발을 하다보면, 분명 암호 파일을 프로젝트 폴더 내부에서 관리하게 되는 경우가 발생합니다.
이 경우 github에 해당 파일을 올리게 되면 모두가 암호를 볼 수 있겠죠?
또한 로그, 컴파일 파일 같은 용량이 큰 파일: Java 컴파일 파일(.class), 모듈파일(vendor, node_modules)같은 파일들 또한 git으로 다 관리하기에 무리가 있습니다.
이런 경우 우리는 .gitignore을 이용할 수 있습니다.
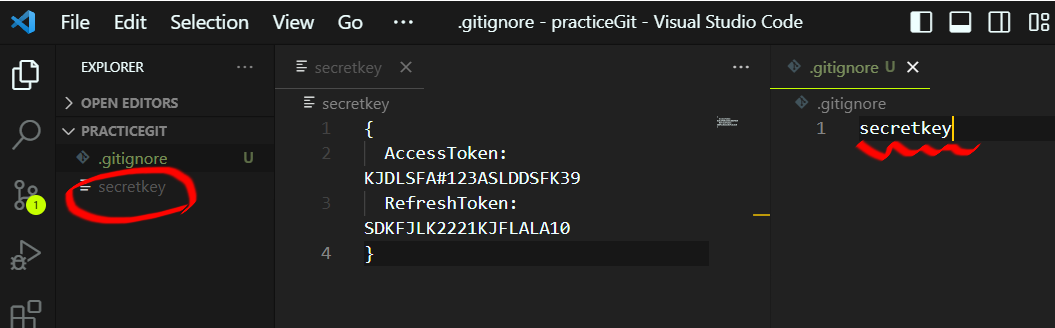
프로젝트 폴더 내부에서 특정한 파일만 제외하고 싶을 때, .gitignore라는 파일을 만들고, 파일 내부에 제외하고자 하는 파일명 혹은 폴더명을 적어주시면 됩니다.
vscode 상에서 해당 파일의 색깔이 회색으로 바뀌는 것을 확인할 수 있습니다.
이미 key 파일이 git으로 관리되고 있을 때
git에서 이미 해당 파일을 add, commit까지 하여서 git이 대상 파일을 인지하고 있다면 파일이 cache (임시 저장소) 안에 남아있기 때문에, .gitignore 안에 파일명을 추가해도 제외되지 않습니다.
이미 git으로 관리되는 파일을 제외하기 위해서는 임시저장소의 파일을 삭제해주는 작업이 필요합니다.
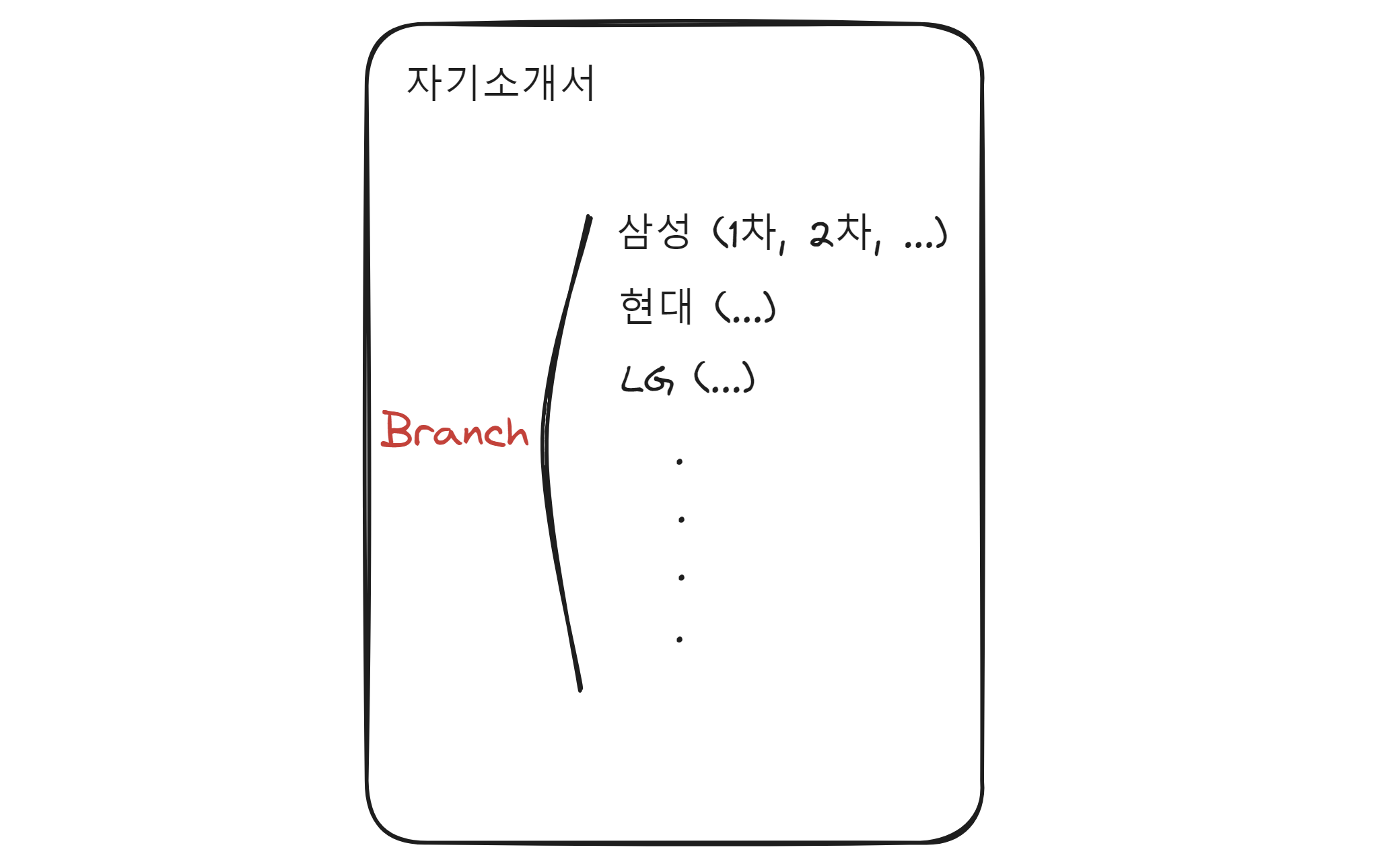
git에는 branch라는 개념이 있습니다. branch는 분기라는 뜻을 가지고 있는데요, 말그대로 버전 관리의 분기점을 만드는 기능입니다. 버전 관리를 분기한다는 것은 현재 작업중인 상태(파일, 커밋기록) 그대로, 아예 별도로 관리되는 새로운 폴더를 하나 더 만드는 것입니다.
기업별 자기소개서를 쓴다고 한다면 각 기업에 맞는 특화된 자기소개서를 준비해야 하겠지요? 여기서 자기소개서라는 뿌리는 같지만 분기별로 나누어 각각의 새로운 관리 대상을 버전관리하게 되는데 이것이 브랜치 입니다. 브랜치를 통해 우리는 원할 때마다 브랜치를 옮겨다니면서 작업을 할 수 있게 됩니다.
개발에 있어서는 개발 절차 상의 안전성 때문에 사용하게 됩니다.
현재 작업 중인 내용을 유지하면서, 파일과 커밋 기록을 별도로 관리하고자 할 때 브랜치를 분기하게 됩니다.
브랜치를 분기하게 되면, 그때부터는 파일과 커밋 기록이 완전히 별도로 관리됩니다.
브랜치는 얼마든지 추가로 더 만들 수 있는데, 항상 원본 브랜치가 있어야 분기할 수 있습니다.
branch 생성
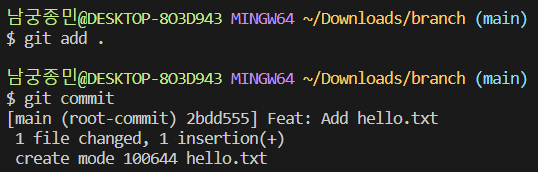
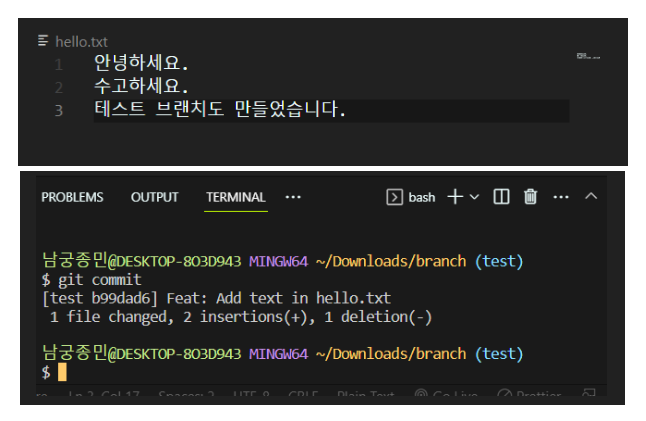
branch 라는 폴더를 만들고 hello.txt 파일을 만들어 안녕하세요 라는 텍스트를 입력하겠습니다.
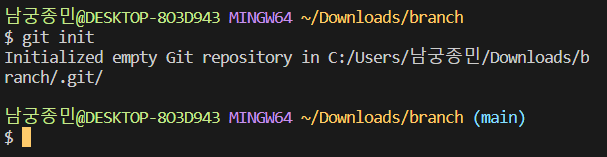
그상태로 git init을 사용해 git으로 폴더를 관리해줍니다.
main 이라는 브랜치 명을 쓰게 된 것은 2020년의 흑인 운동의 일환으로 master / slave 등의 용어에 대한 정화의 필요하다는 의식이 생기게 되면서 Github에서 기본 브랜치 명을 master에서 main 으로 변경되게 되었고 git 자체적으로도 main 브랜치를 기본 이름으로 쓰도록 권장되고 있습니다.
git init을 할 때 브랜치 명이 master로 기본 설정 되어있다면 아래 명령어를 통해 main으로 바꿀 수 있습니다.
이제 add commit을 해서 현재 파일 상태를 기록해주겠습니다.
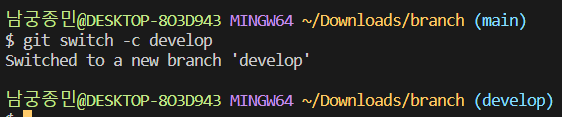
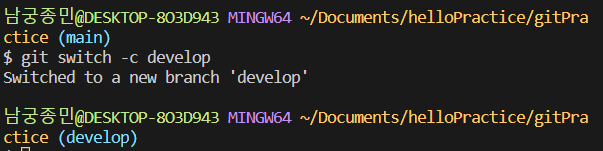
분기를 해보겠습니다. 브랜치를 전환할 때는 git switch 명령어를 통해 브랜치를 전환할 수 있습니다. 이 때 새로운 브랜치를 만들면서 전환하고 싶다면 -c 옵션을 같이 입력해주시면 됩니다. (브랜치를 만들기만하고 이동하고 싶지 않을 때는 git branch [브랜치명] 명령어를 이용하면 됩니다.)
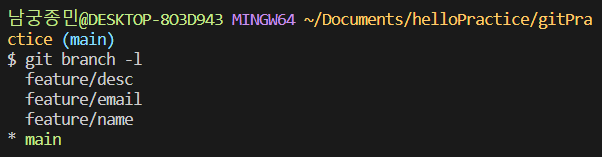
git branch –list 명령어를 통해 현재 보유하고있는 브랜치들을 확인할 수 있습니다.
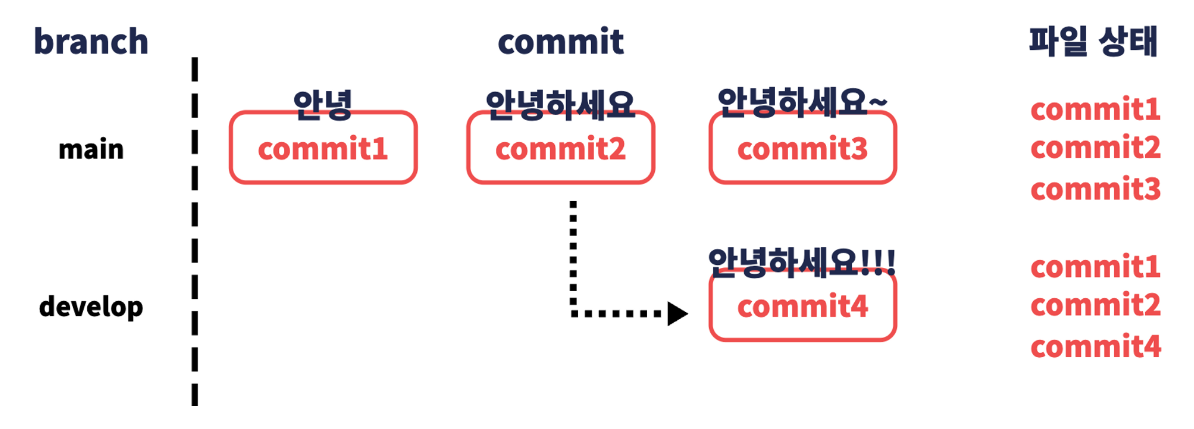
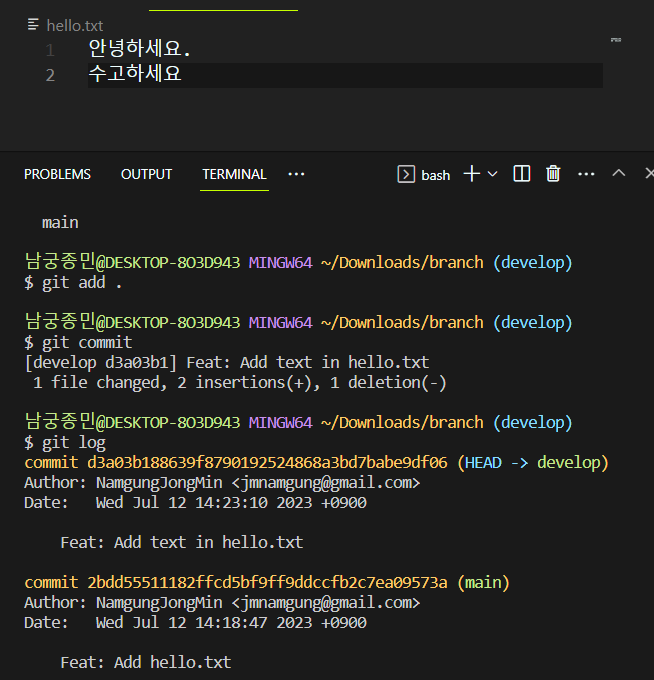
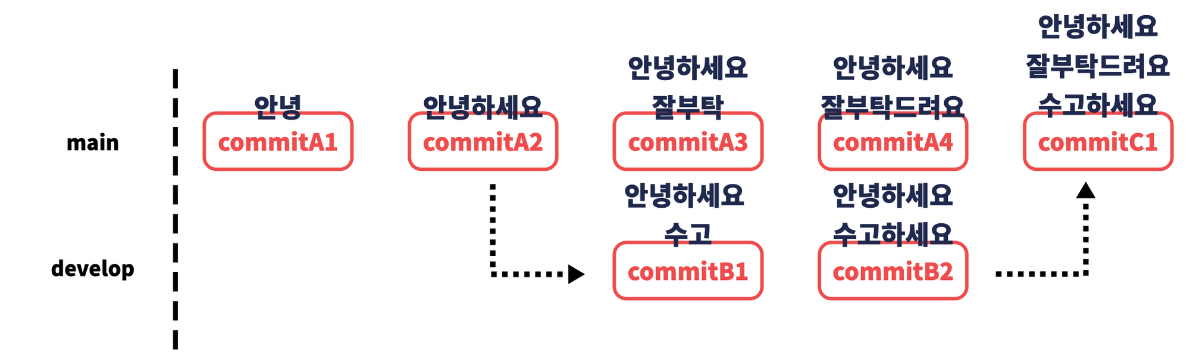
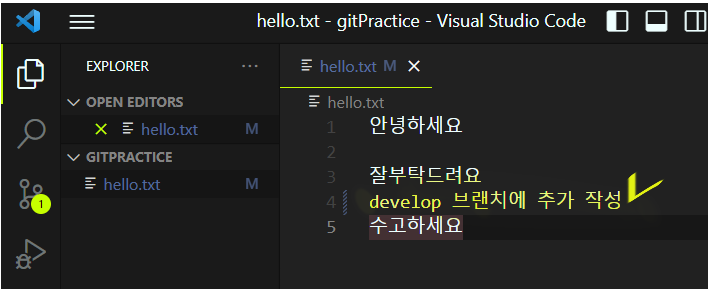
이제 develop 브랜치에서 파일에 ‘수고하세요’라는 텍스트를 입력하고 커밋해보겠습니다.
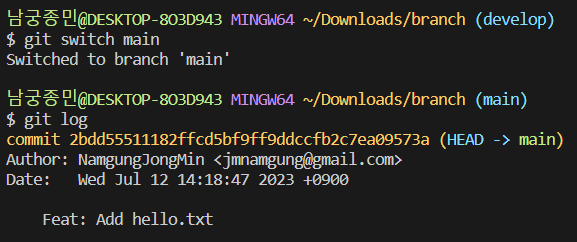
develop 브랜치에서는 새로운 커밋이 생겼는데 main 브랜치에선 어떨까요? main 브랜치를 옮겨가서 로그를 확인해봅시다.
develop 브랜치와 main 브랜치의 커밋이 별도로 관리된다는 것을 확인할 수 있습니다.
develop 브랜치로 돌아가 다시 분기해보겠습니다. test 브랜치를 새로 만들어 주겠습니다. 그리고 텍스트도 추가해주겠습니다.
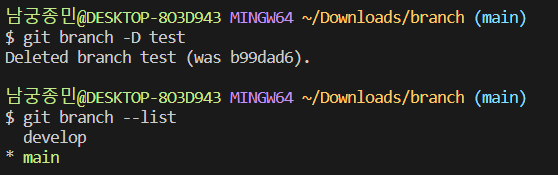
브랜치 삭제
이제 만든 test 브랜치를 삭제해보겠습니다. 삭제에는 git branch -D (브랜치명) 명령어를 사용합니다. 삭제하려는 브랜치를 제외한 다른 브랜치로 옮겨서 명령어를 입력해줍니다. git branch –list로 결과도 확인해보겠습니다.
브랜치 병합
git merge 명령어는 서로 다른 branch의 작업 내용을 하나의 branch 로 통합하기 위한 명령어 입니다.
이 때 통합하는 merge 행위 자체가 하나의 커밋으로서 남게 됩니다.
새로운 폴더를 생성해서 실습해보겠습니다. hello.txt를 생성해서 다음과 같은 텍스트를 입력해주고 git init을 통해 관리하게 하겠습니다.
이후에는 develop 브랜치를 만들어서 텍스트를 추가하고 다시 커밋까지 해주겠습니다.
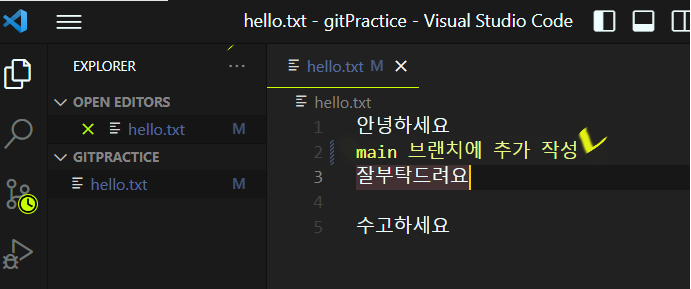
다시 main 브랜치로 전환해서 텍스트를 또 추가하고 커밋을 해주겠습니다.
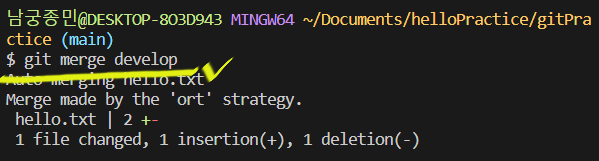
이제 merge 명령어를 통해 main브랜치에서 develop브랜치를 병합해보겠습니다. ‘메인브랜치로 가서 -> develop 을 병합한다’
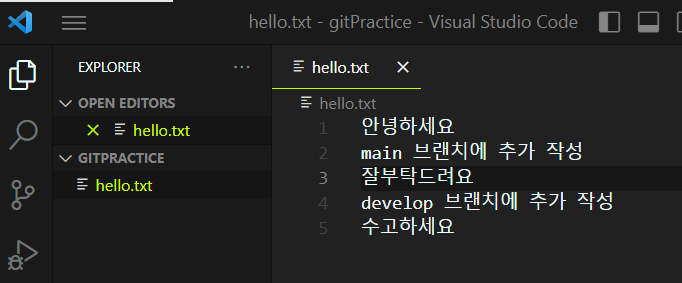
두 브랜치에서 각각 작성된 텍스트가 main 브랜치에서 병합되어 전부 나타나는 것을 확인했습니다.
아래 명령어를 통해서 커밋 기록이 어떤식으로 이루어져있는지를 좀 더 직관적으로 확인할 수 있습니다.
1
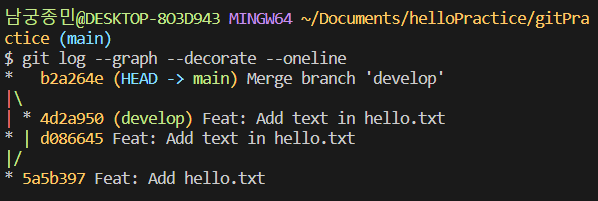
git log --graph --decorate --oneline
위에 설명한 그림처럼 커밋 기록이 이루어진 것을 확인할 수 있습니다.
merge conflict
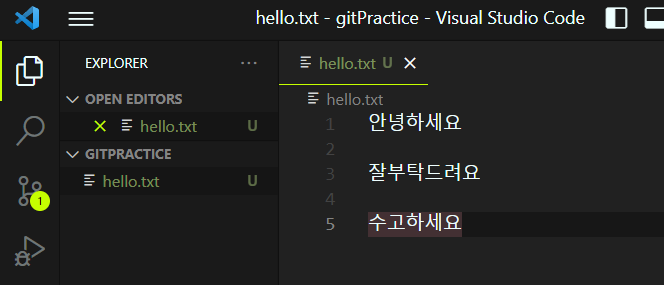
바로 위 예시에서 왜 중간 공간을 띄어놓고 각각 2번줄 4번줄에 텍스트를 추가했을까요?
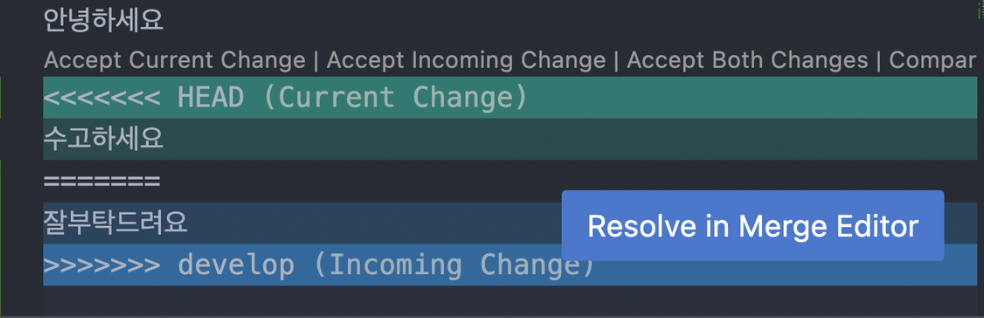
두 브랜치를 병합할 때 만약 각 브랜치에서 서로 같은 부분을 수정했다면 git의 입장에서 어떤 브랜치를 우선해야할지 결정할 수 없게 됩니다.
이 때 사용자에게 둘중 어떤 것을 기준하여 확정할지를 정해달라고 하는 말을 건네는 것이 바로 merge conflict 입니다!
(merge conflict 예시)
여기서 accept current change를 선택하면 현재 우리가 있는 main브랜치의 내용을 따르게 되고, accept incoming change를 누르면 병합하는 develop 브랜치를 따르게 됩니다. 또는 직접 내용을 수정해서 merge하는 것도 가능합니다.
Git으로 협업할 때 중요한 부분을 배울 수 있습니다. 여러 사람이 동시에 한 파일의 같은 부분을 작업해서는 안된다는 것입니다. 애초에 작업을 분담해 서로 다른 파일/ 다른 부분을 작업하도록 분담하는 것이 conflict를 방지하기 위한 방법입니다.
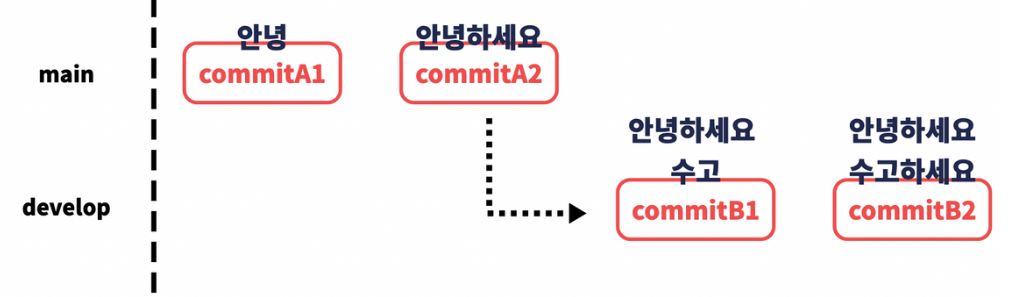
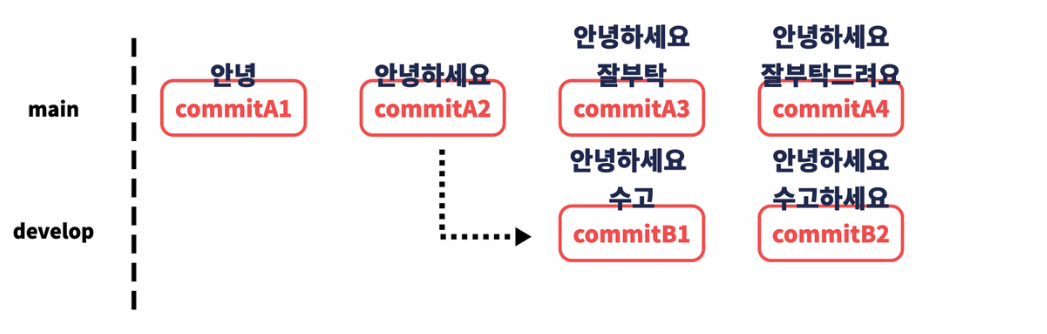
fast-forward
main 브랜치에서 develop 브랜치로 분기를 하고 main 브랜치를 건드리지는 않은 상태에서 develop 브랜치만을 수정하고 merge하는 경우를 상상해봅시다.
병합을 시도하면 fast-forword라는 문구가 뜨게되는데요, 위 상황같은 경우에는 merge conflict가 날 상황도 생기지 않고 그저 main에서 계속 작업을 했을 때와 같은 상황으로 보여지는데 이 경우를 fast-forward라고 합니다.
이 경우에는 따로 merge 커밋이 생기지도 않고 그저 develop 브랜치의 커밋이 main 브랜치에 병합되면서 아래와 같은 커밋 기록이 만들어지게 됩니다.
만약 기존처럼 줄기가 나눠진 형태로 커밋 기록을 남기고 싶다면 –no-ff를 붙여 merge명령어를 입력하면 됩니다.
1
git merge develop --no--ff
fast-forward의 장단점
장점: 분기점이 남지 않기 때문에 커밋 기록을 더 직관적으로 볼 수 있다.
단점: merge했다는 기록도 없고, 분기점도 없다.
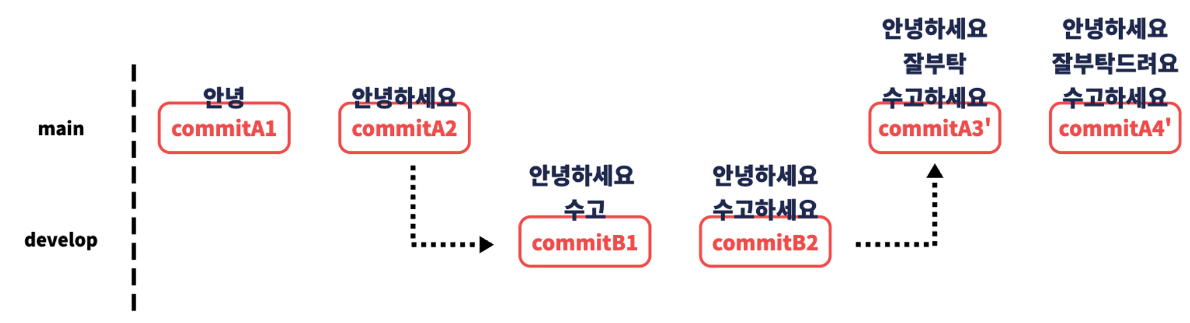
rebase
rebase는 특정 브랜치를 기준으로 놓고 커밋 이력을 정렬하는 명령어입니다. non-fast-forward를 fast-forward로 만드는 명령어라고 생각하시면 됩니다.
아래와 같은 형태로 브랜치가 나눠져 있다면
줄기가 나뉘지 않고 fast-forward로 커밋 이력이 정리되게 됩니다.
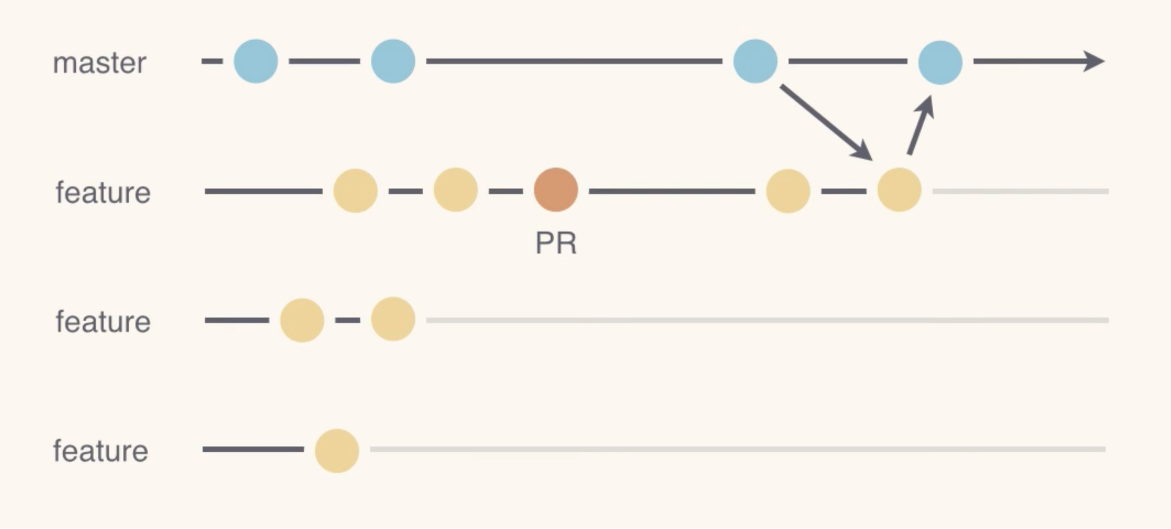
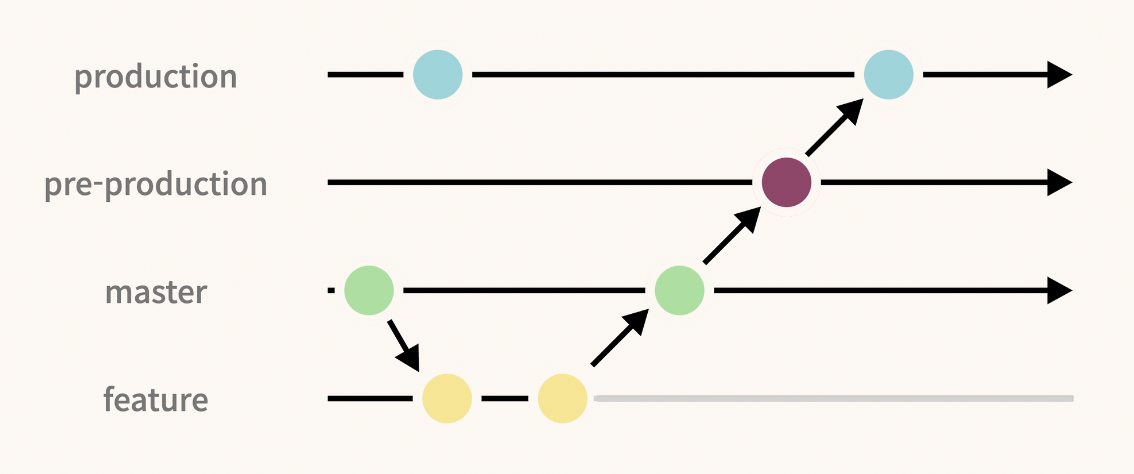
Pull Request
pull request는 ‘나의 담당 브랜치에서 작업이 완료되었으니, 이 브랜치의 코드를 가져가서 병합해주세요’라는 요청을 보내는 것입니다.
pull request를 하는 이유는
내가 작성한 코드가 바로 적용되었을 때 발생할 수 있는 문제를 미리 방지
현재 코드에 대한 코드 리뷰를 진행
프로젝트에 대한 진행 상황을 관리 등이 있습니다.
pull request 사용한 병합
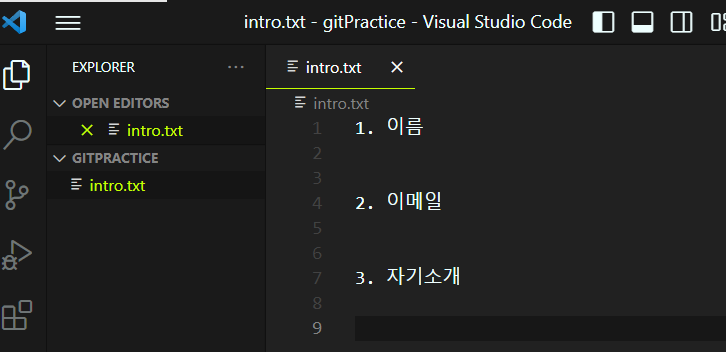
intro.txt 파일을 만들어서 텍스트를 입력해주고 git init > add > commit 해주겠습니다.
또 각 목차별로 branch를 만들어서 각 내용을 작성하고 이를 main 브랜치로 병합하겠습니다.
이후에는 github에서 레포지토리를 새로 만들어 로컬저장소와 연결해주겠습니다.
git push –all 명령어를 이용해 모든 브랜치와 commit 내역을 github로 올리겠습니다.
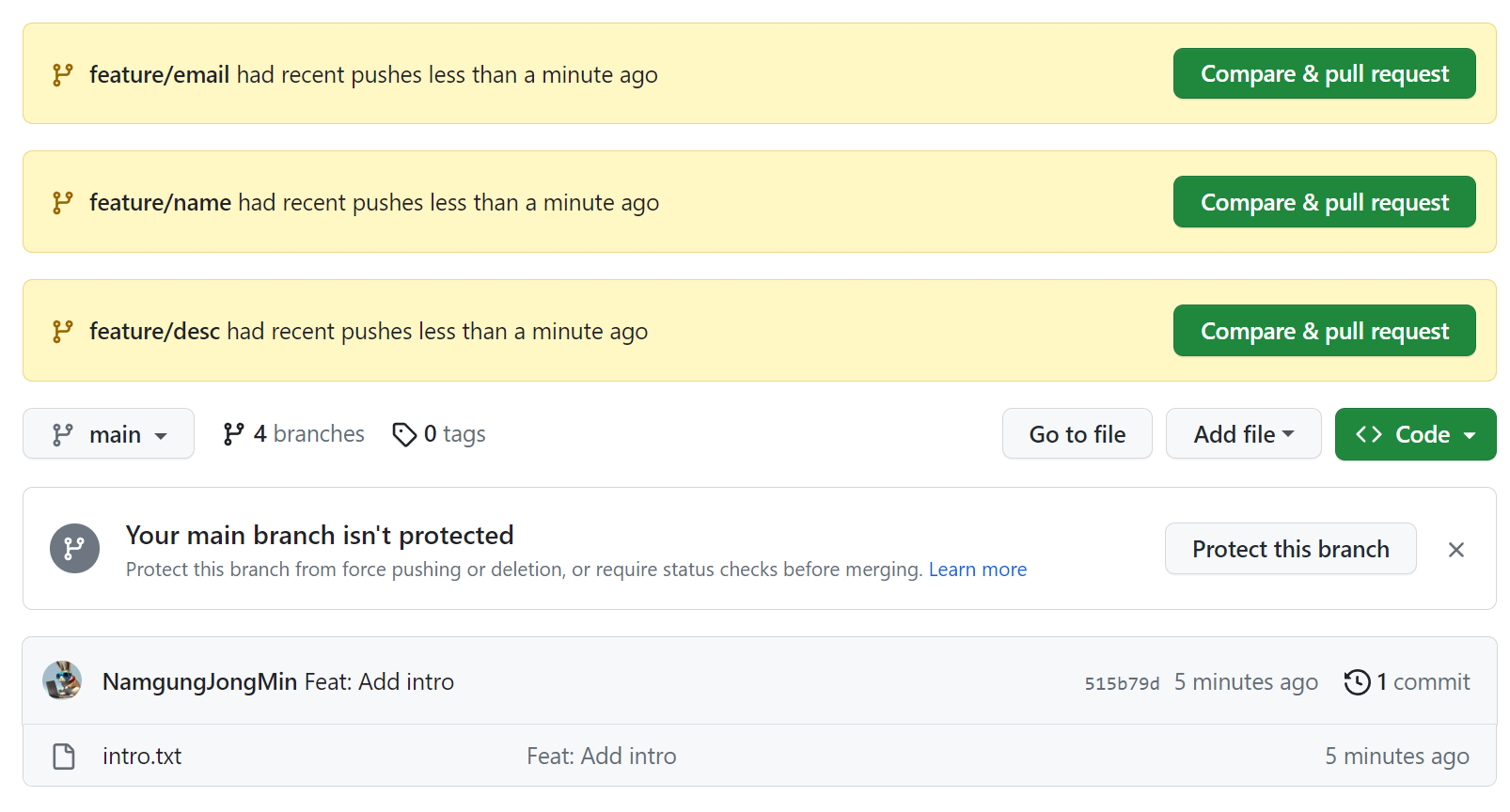
그러면 github에서 각 브랜치들을 확인할 수 있고 main을 기반으로 각 브랜치를 머지해 달라는 메시지도 확인할 수 있습니다.
github에서 pull request 요청을 보내 main에 각 브랜치의 내용을 병합할 수 있습니다.
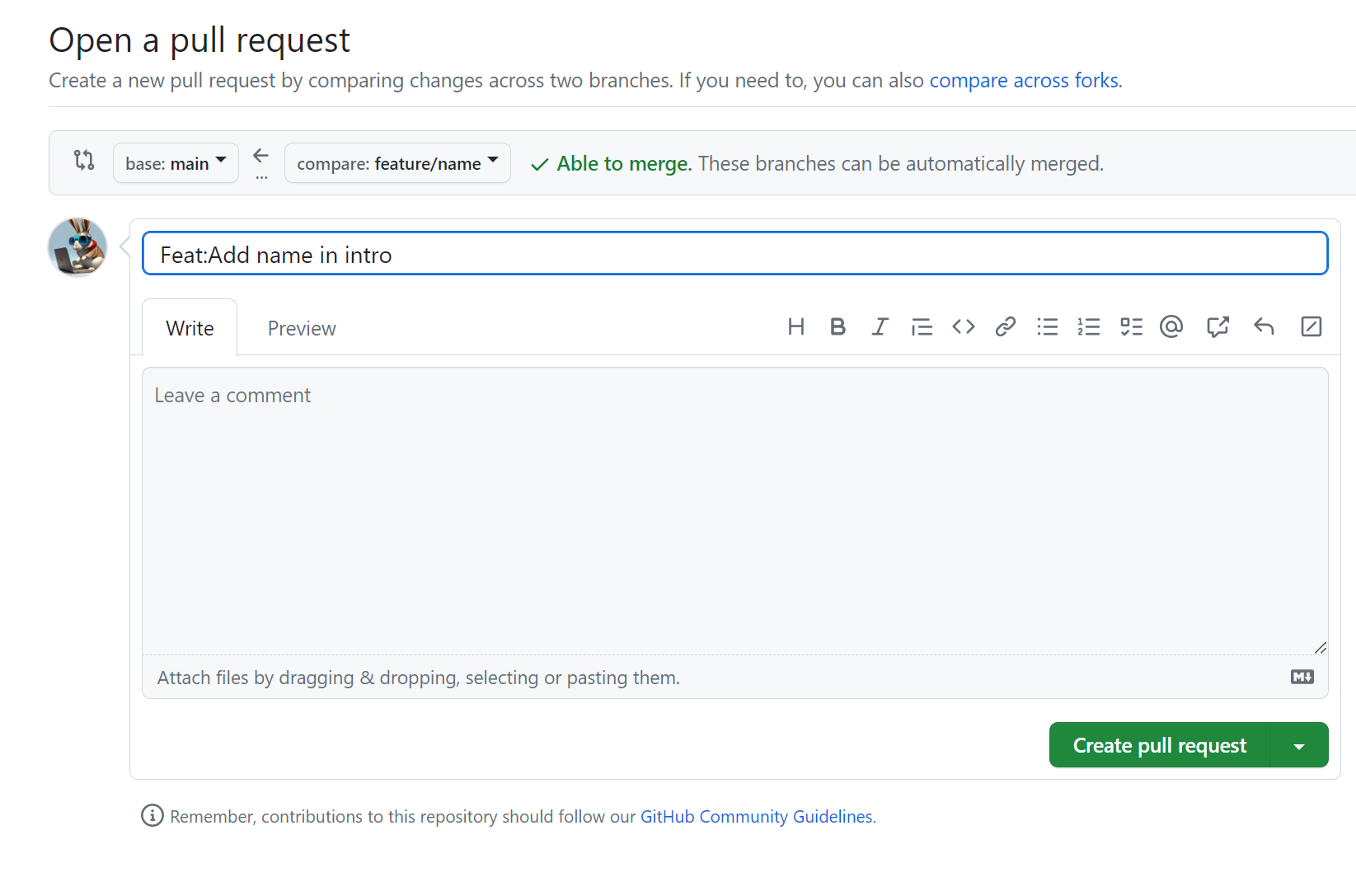
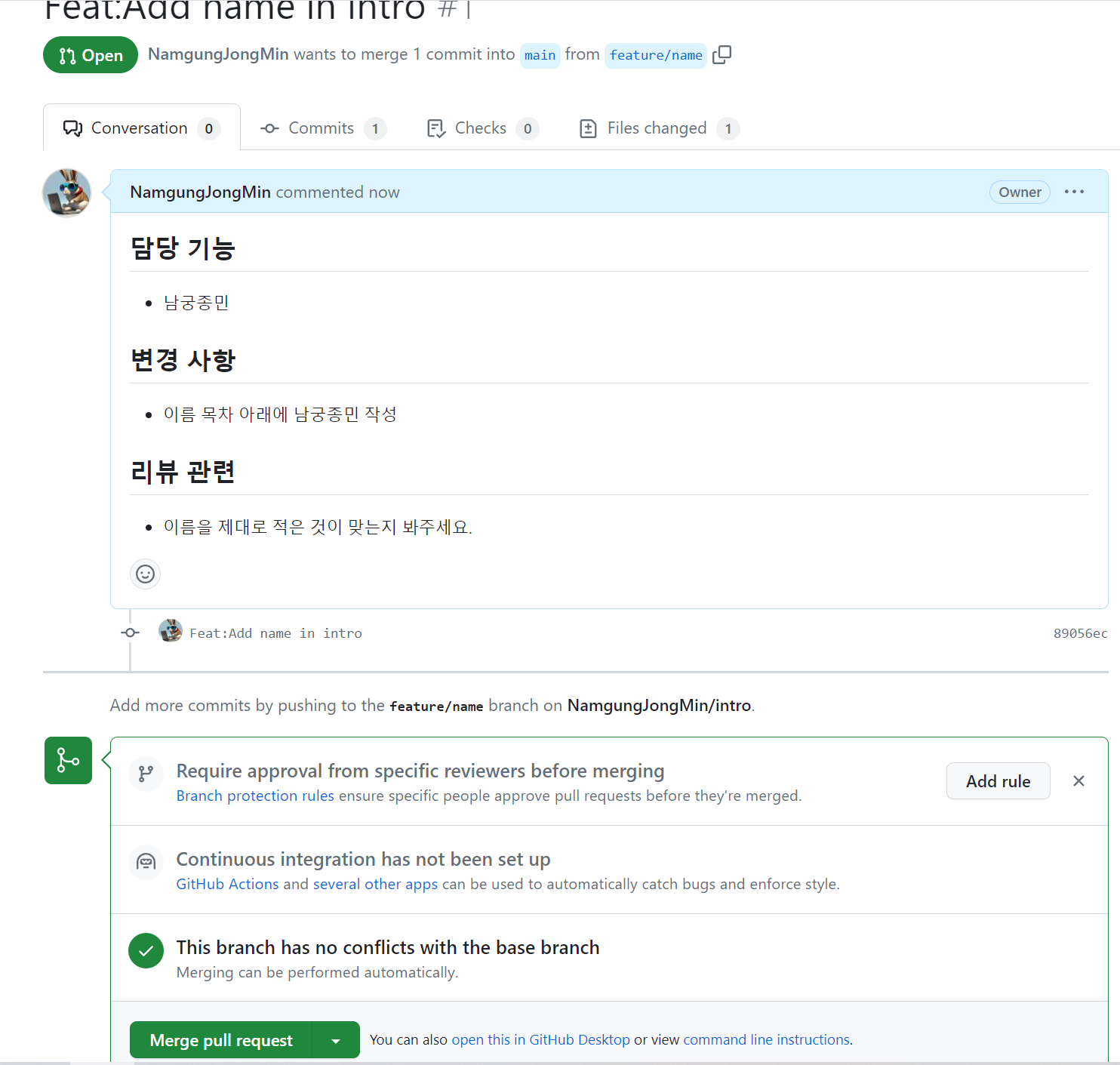
보통 pull request를 작성할 때에는 해당 부분을 왜 작성했고, 이전에 비해 어떤 것이 바뀌었는지, 그리고 코드리뷰 관련 요청사항등을 작성하게 됩니다.
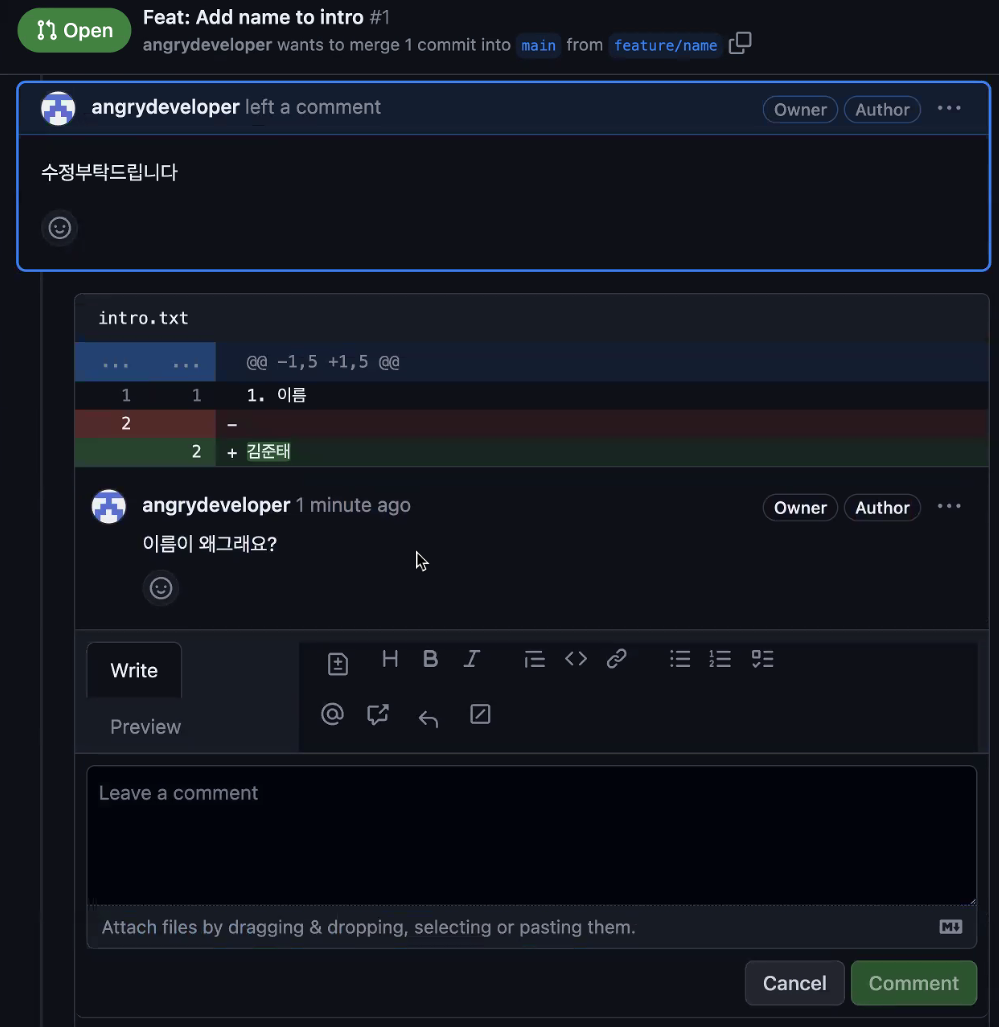
그러면 pull request 페이지가 생성되고 그 페이지에서 개발자들간 코멘트를 주거나 코드리뷰를 하는 등 활동을 할 수 있습니다.
Confirm merge 버튼을 누르게 되면 main에 name 브랜치가 merge 되는 것을 확인할 수 있습니다.
또한 브랜치를 merge하여 브랜치의 사용이유가 사라졌으니 삭제해 달라는 메시지가 뜨는 것도 확인할 수 있습니다. 버튼을 눌러 삭제해주겠습니다.
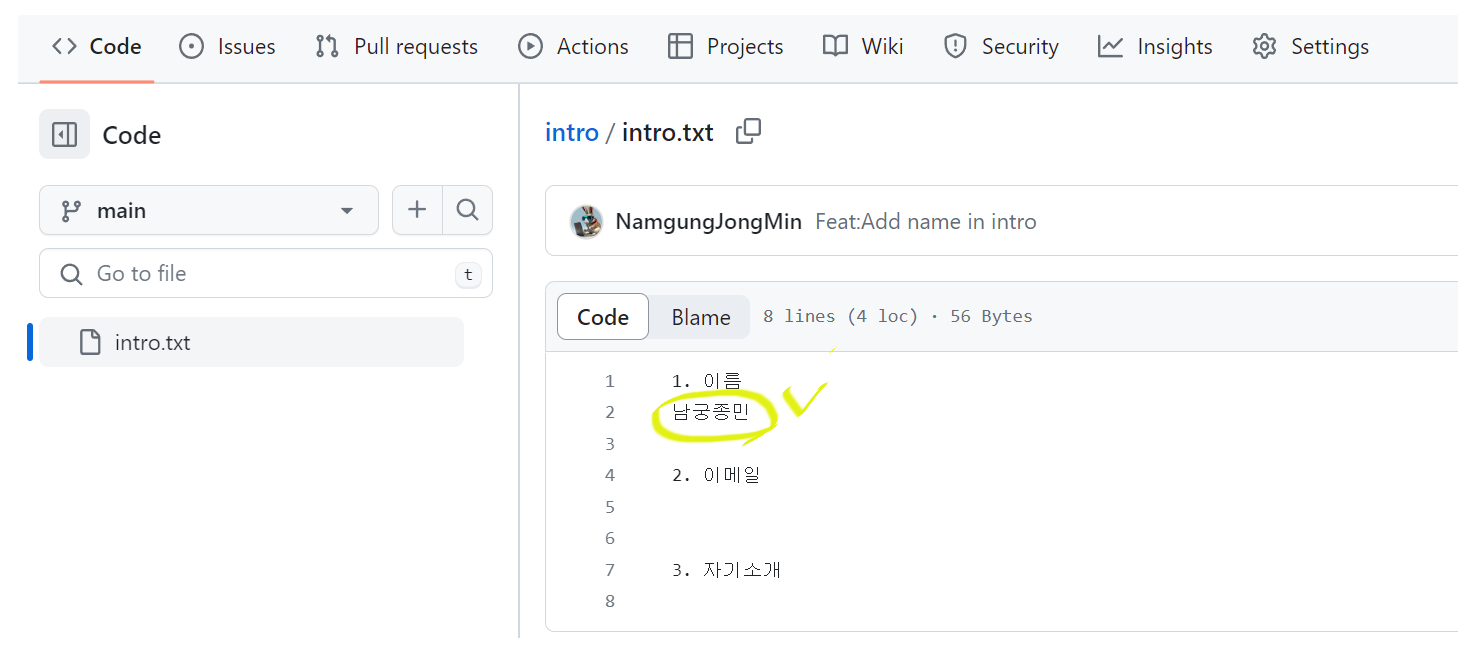
main 에 병합된 name 브랜치의 내용들을 확인할 수 있습니다.
github 수정사항 가져오기
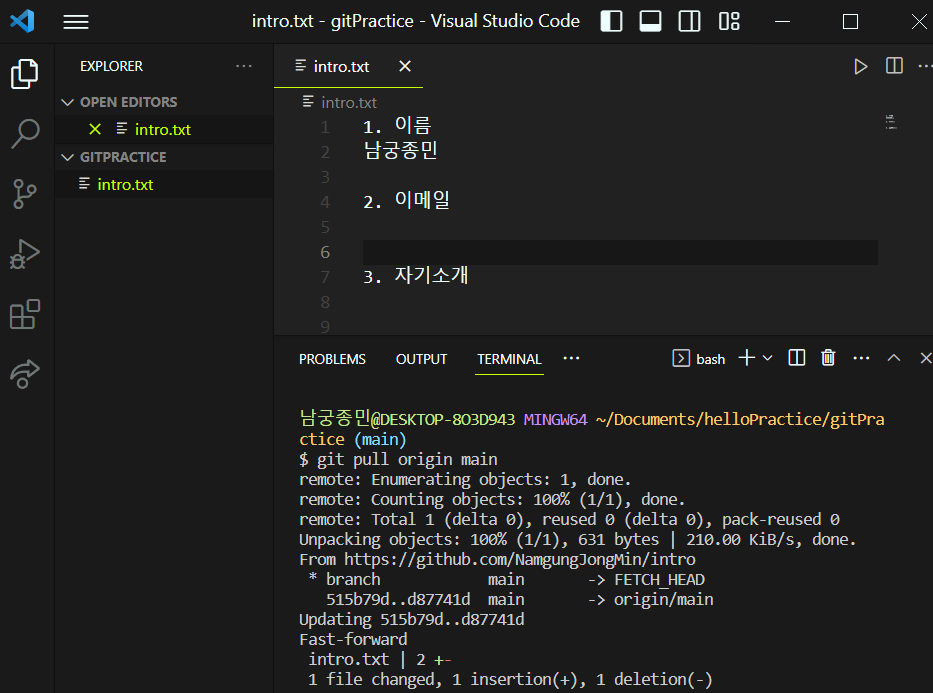
원격저장소인 github의 수정사항을 로컬 저장소에도 반영해야겠죠? 이 때 사용하는 명령어는 git pull 입니다.
다만 여기서 원격 저장소에서 삭제한 브랜치는 로컬 저장소에 반영이 되지 않기 때문에 수동적으로 지워주셔야 합니다.